 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Relation between Internal Language Model and Sequence Discriminative Training for Neural Transducers
Paper and Code
Sep 25, 2023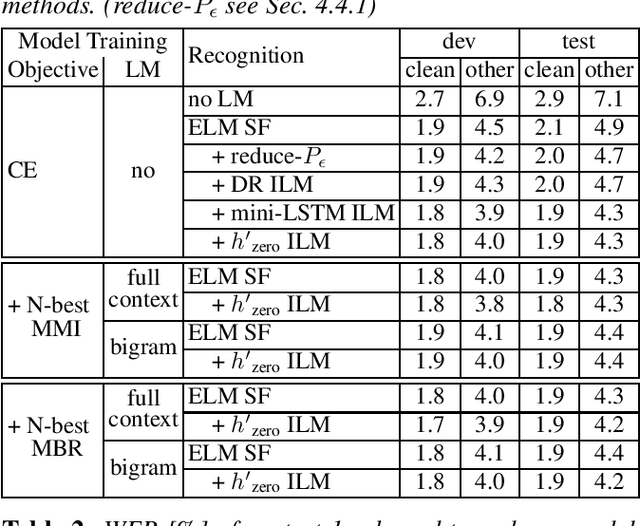



Internal language model (ILM) subtraction has been widely applied to improve the performance of the RNN-Transducer with external language model (LM) fusion for speech recognition. In this work, we show that sequence discriminative training has a strong correlation with ILM subtraction from both theoretical and empirical points of view. Theoretically, we derive that the global optimum of maximum mutual information (MMI) training shares a similar formula as ILM subtraction. Empirically, we show that ILM subtraction and sequence discriminative training achieve similar performance across a wide range of experiments on Librispeech, including both MMI and minimum Bayes risk (MBR) criteria, as well as neural transducers and LMs of both full and limited context. The benefit of ILM subtraction also becomes much smaller after sequence discriminative training. We also provide an in-depth study to show that sequence discriminative training has a minimal effect on the commonly used zero-encoder ILM estimation, but a joint effect on both encoder and prediction + joint network for posterior probability reshaping including both ILM and blank suppression.