 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Promise of the Stochastic Generalized Gauss-Newton Method for Training DNNs
Paper and Code
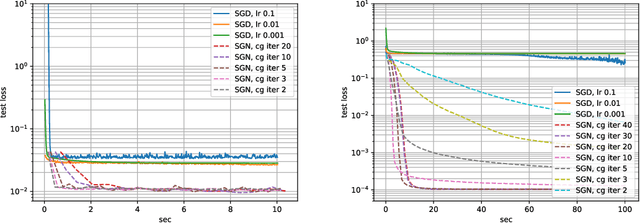
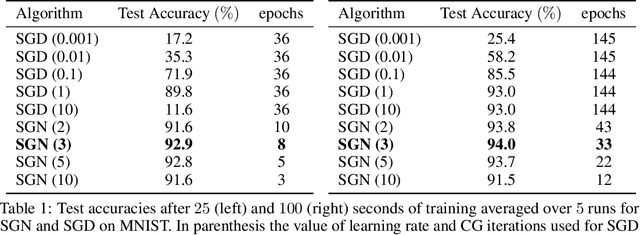

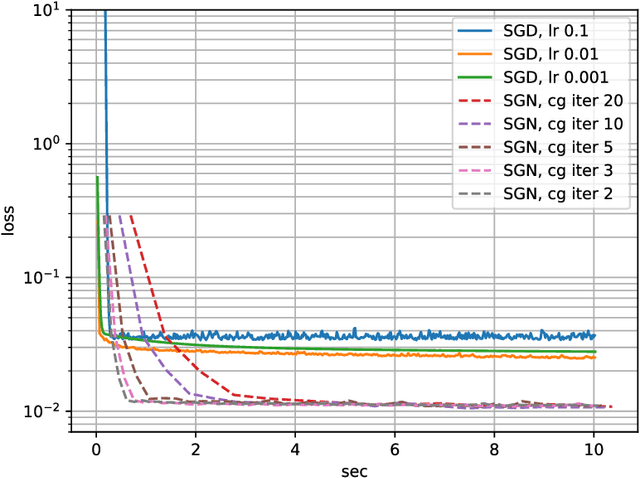
Following early work on Hessian-free methods for deep learning, we study a stochastic generalized Gauss-Newton method (SGN) for training DNNs. SGN is a second-order optimization method, with efficient iterations, that we demonstrate to often require substantially fewer iterations than standard SGD to converge. As the name suggests, SGN uses a Gauss-Newton approximation for the Hessian matrix, and, in order to compute an approximate search direction, relies on the conjugate gradient method combined with forward and reverse automatic differentiation. Despite the success of SGD and its first-order variants, and despite Hessian-free methods based on the Gauss-Newton Hessian approximation having been already theoretically proposed as practical methods for training DNNs, we believe that SGN has a lot of undiscovered and yet not fully displayed potential in big mini-batch scenarios. For this setting, we demonstrate that SGN does not only substantially improve over SGD in terms of the number of iterations, but also in terms of runtime. This is made possible by an efficient, easy-to-use and flexible implementation of SGN we propose in the Theano deep learning platform, which, unlike Tensorflow and Pytorch, supports forward automatic differentiation. This enables researchers to further study and improve this promising optimization technique and hopefully reconsider stochastic second-order methods as competitive optimization techniques for training DNNs; we also hope that the promise of SGN may lead to forward automatic differentiation being added to Tensorflow or Pytorch. Our results also show that in big mini-batch scenarios SGN is more robust than SGD with respect to its hyperparameters (we never had to tune its step-size for our benchmarks!), which eases the expensive process of hyperparameter tuning that is instead crucial for the performance of first-order methods.