 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the iterative refinement of densely connected representation levels for semantic segmentation
Paper and Code
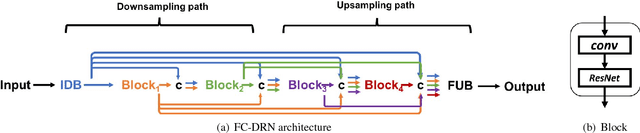



State-of-the-art semantic segmentation approaches increase the receptive field of their models by using either a downsampling path composed of poolings/strided convolutions or successive dilated convolutions. However, it is not clear which operation leads to best results. In this paper, we systematically study the differences introduced by distinct receptive field enlargement methods and their impact on the performance of a novel architecture, called Fully Convolutional DenseResNet (FC-DRN). FC-DRN has a densely connected backbone composed of residual networks. Following standard image segmentation architectures, receptive field enlargement operations that change the representation level are interleaved among residual networks. This allows the model to exploit the benefits of both residual and dense connectivity patterns, namely: gradient flow, iterative refinement of representations, multi-scale feature combination and deep supervision. In order to highlight the potential of our model, we test it on the challenging CamVid urban scene understanding benchmark and make the following observations: 1) downsampling operations outperform dilations when the model is trained from scratch, 2) dilations are useful during the finetuning step of the model, 3) coarser representations require less refinement steps, and 4) ResNets (by model construction) are good regularizers, since they can reduce the model capacity when needed. Finally, we compare our architecture to alternative methods and report state-of-the-art result on the Camvid dataset, with at least twice fewer parameters.