 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effectiveness of Least Squares Generative Adversarial Networks
Paper and Code

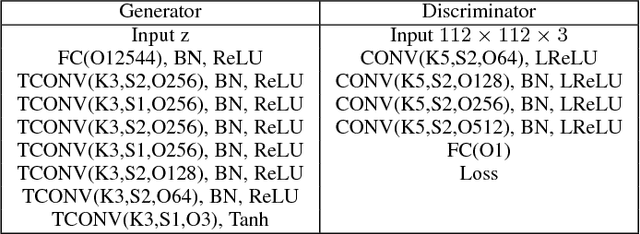
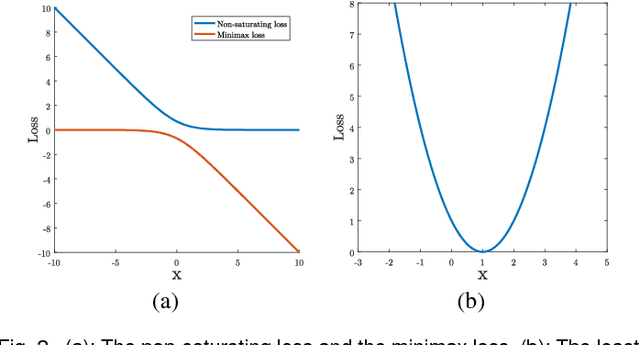

Unsupervised learning with generative adversarial networks (GANs) has proven to be hugely successful. Regular GANs hypothesize the discriminator as a classifier with the sigmoid cross entropy loss function. However, we found that this loss function may lead to the vanishing gradients problem during the learning process. To overcome such a problem, we propose in this paper the Least Squares Generative Adversarial Networks (LSGANs) which adopt the least squares loss for both the discriminator and the generator. We show that minimizing the objective function of LSGAN yields minimizing the Pearson $\chi^2$ divergence. We also show that the derived objective function that yields minimizing the Pearson $\chi^2$ divergence performs better than the classical one of using least squares for classification. There are two benefits of LSGANs over regular GANs. First, LSGANs are able to generate higher quality images than regular GANs. Second, LSGANs perform more stably during the learning process. For evaluating the image quality, we conduct both qualitative and quantitative experiments, and the experimental results show that LSGANs can generate higher quality images than regular GANs. Furthermore, we evaluate the stability of LSGANs in two groups. One is to compare between LSGANs and regular GANs without gradient penalty. We conduct three experiments, including Gaussian mixture distribution, difficult architectures, and a newly proposed method --- datasets with small variability, to illustrate the stability of LSGANs. The other one is to compare between LSGANs with gradient penalty (LSGANs-GP) and WGANs with gradient penalty (WGANs-GP). The experimental results show that LSGANs-GP succeed in training for all the difficult architectures used in WGANs-GP, including 101-layer ResNet.