 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the convergence of group-sparse autoencoders
Paper and Code
Feb 13, 2021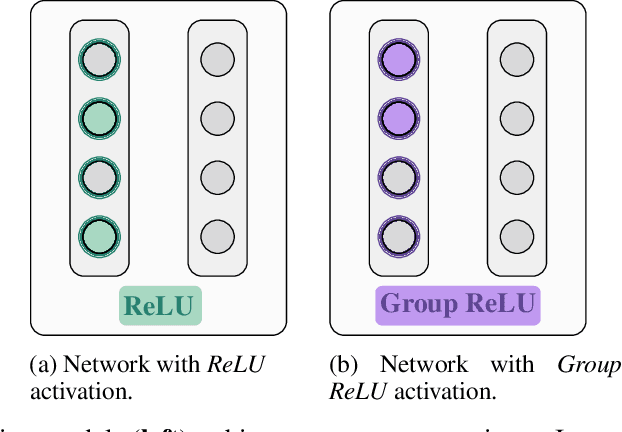
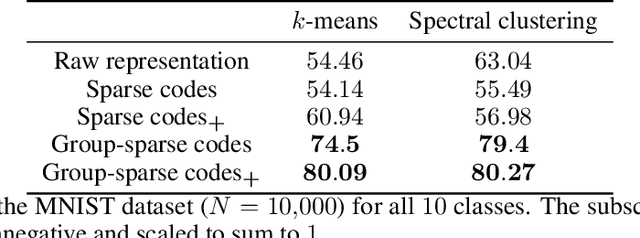
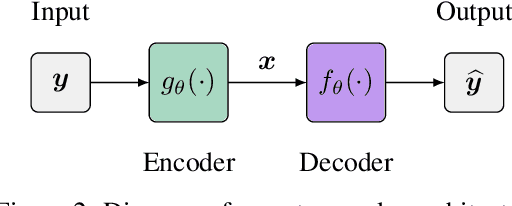
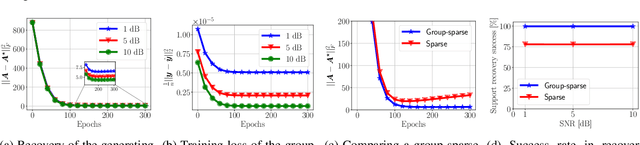
Recent approaches in the theoretical analysis of model-based deep learning architectures have studied the convergence of gradient descent in shallow ReLU networks that arise from generative models whose hidden layers are sparse. Motivated by the success of architectures that impose structured forms of sparsity, we introduce and study a group-sparse autoencoder that accounts for a variety of generative models, and utilizes a group-sparse ReLU activation function to force the non-zero units at a given layer to occur in blocks. For clustering models, inputs that result in the same group of active units belong to the same cluster. We proceed to analyze the gradient dynamics of a shallow instance of the proposed autoencoder, trained with data adhering to a group-sparse generative model. In this setting, we theoretically prove the convergence of the network parameters to a neighborhood of the generating matrix. We validate our model through numerical analysis and highlight the superior performance of networks with a group-sparse ReLU compared to networks that utilize traditional ReLUs, both in sparse coding and in parameter recovery tasks. We also provide real data experiments to corroborate the simulated results, and emphasize the clustering capabilities of structured sparsity models.