 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Sample Complexity of Projection-Free Primal-Dual Methods for Learning Mixture Policies in Markov Decision Processes
Paper and Code
Mar 20, 2019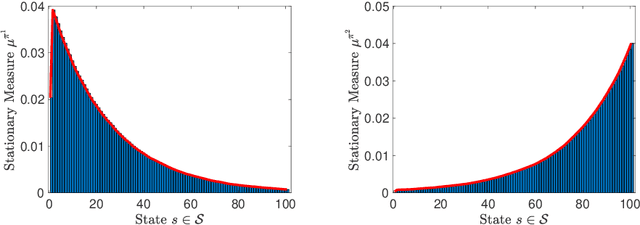
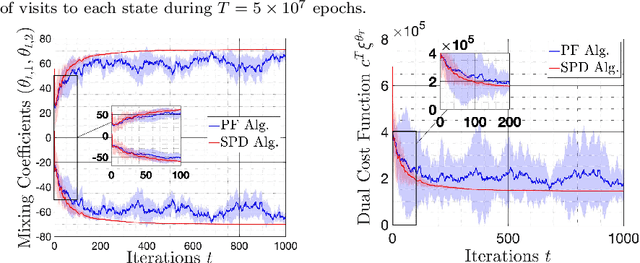
We study the problem of learning policy of an infinite-horizon, discounted cost, Markov decision process (MDP) with a large number of states. We compute the actions of a policy that is nearly as good as a policy chosen by a suitable oracle from a given mixture policy class characterized by the convex hull of a set of known base policies. To learn the coefficients of the mixture model, we recast the problem as an approximate linear programming (ALP) formulation for MDPs, where the feature vectors correspond to the occupation measures of the base policies defined on the state-action space. We then propose a projection-free stochastic primal-dual method with the Bregman divergence to solve the characterized ALP. Furthermore, we analyze the probably approximately correct (PAC) sample complexity of the proposed stochastic algorithm, namely the number of queries required to achieve near optimal objective value. We also propose a modification of our proposed algorithm with the polytope constraint sampling for the smoothed ALP, where the restriction to lower bounding approximations are relaxed. In addition, we apply the proposed algorithms to a queuing problem, and compare their performance with a penalty function algorithm. The numerical results illustrates that the primal-dual achieves better efficiency and low variance across different trials compared to the penalty function method.