 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Metric Learning for Audio-Text Cross-Modal Retrieval
Paper and Code
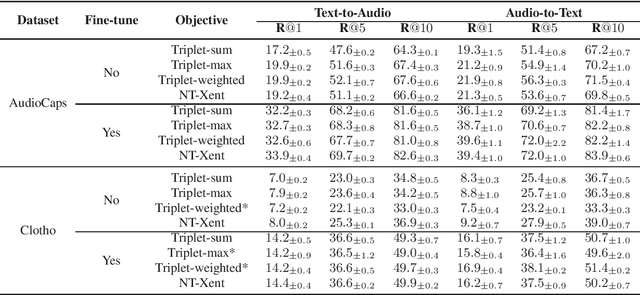
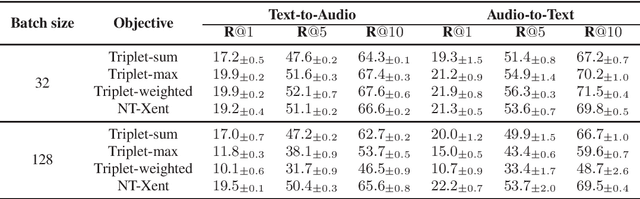
Audio-text retrieval aims at retrieving a target audio clip or caption from a pool of candidates given a query in another modality. Solving such cross-modal retrieval task is challenging because it not only requires learning robust feature representations for both modalities, but also requires capturing the fine-grained alignment between these two modalities. Existing cross-modal retrieval models are mostly optimized by metric learning objectives as both of them attempt to map data to an embedding space, where similar data are close together and dissimilar data are far apart. Unlike other cross-modal retrieval tasks such as image-text and video-text retrievals, audio-text retrieval is still an unexplored task. In this work, we aim to study the impact of different metric learning objectives on the audio-text retrieval task. We present an extensive evaluation of popular metric learning objectives on the AudioCaps and Clotho datasets. We demonstrate that NT-Xent loss adapted from self-supervised learning shows stable performance across different datasets and training settings, and outperforms the popular triplet-based losses.