 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Finite-Sample Analysis of Offline Reinforcement Learning with Deep ReLU Networks
Paper and Code
Mar 11, 2021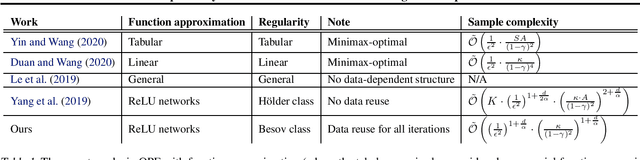
This paper studies the statistical theory of offline reinforcement learning with deep ReLU networks. We consider the off-policy evaluation (OPE) problem where the goal is to estimate the expected discounted reward of a target policy given the logged data generated by unknown behaviour policies. We study a regression-based fitted Q evaluation (FQE) method using deep ReLU networks and characterize a finite-sample bound on the estimation error of this method under mild assumptions. The prior works in OPE with either general function approximation or deep ReLU networks ignore the data-dependent structure in the algorithm, dodging the technical bottleneck of OPE, while requiring a rather restricted regularity assumption. In this work, we overcome these limitations and provide a comprehensive analysis of OPE with deep ReLU networks. In particular, we precisely quantify how the distribution shift of the offline data, the dimension of the input space, and the regularity of the system control the OPE estimation error. Consequently, we provide insights into the interplay between offline reinforcement learning and deep learning.