 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Distinctive Image Captioning via Comparing and Reweighting
Paper and Code
Apr 08, 2022
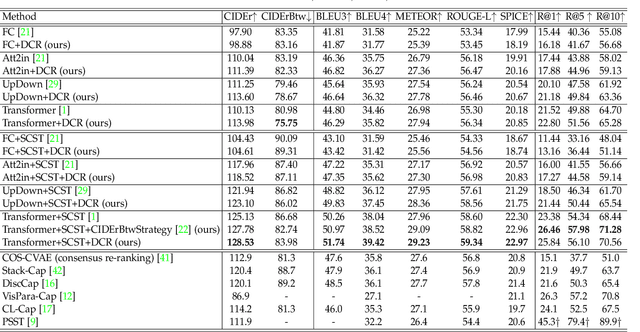


Recent image captioning models are achieving impressive results based on popular metrics, i.e., BLEU, CIDEr, and SPICE. However, focusing on the most popular metrics that only consider the overlap between the generated captions and human annotation could result in using common words and phrases, which lacks distinctiveness, i.e., many similar images have the same caption. In this paper, we aim to improve the distinctiveness of image captions via comparing and reweighting with a set of similar images. First, we propose a distinctiveness metric -- between-set CIDEr (CIDErBtw) to evaluate the distinctiveness of a caption with respect to those of similar images. Our metric reveals that the human annotations of each image in the MSCOCO dataset are not equivalent based on distinctiveness; however, previous works normally treat the human annotations equally during training, which could be a reason for generating less distinctive captions. In contrast, we reweight each ground-truth caption according to its distinctiveness during training. We further integrate a long-tailed weight strategy to highlight the rare words that contain more information, and captions from the similar image set are sampled as negative examples to encourage the generated sentence to be unique. Finally, extensive experiments are conducted, showing that our proposed approach significantly improves both distinctiveness (as measured by CIDErBtw and retrieval metrics) and accuracy (e.g., as measured by CIDEr) for a wide variety of image captioning baselines. These results are further confirmed through a user study.