 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNow You See It, Now You Dont: Adversarial Vulnerabilities in Computational Pathology
Paper and Code
Jun 16, 2021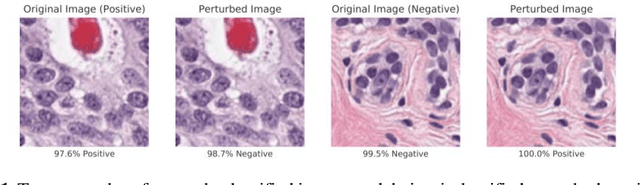

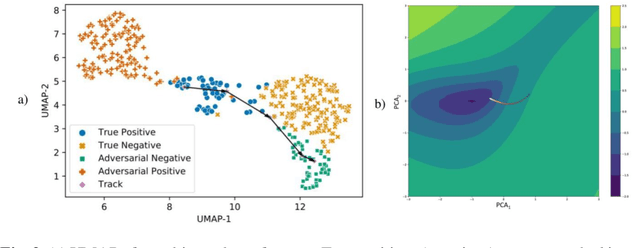
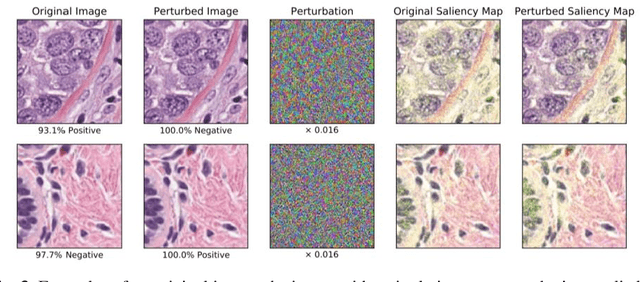
Deep learning models are routinely employed in computational pathology (CPath) for solving problems of diagnostic and prognostic significance. Typically, the generalization performance of CPath models is analyzed using evaluation protocols such as cross-validation and testing on multi-centric cohorts. However, to ensure that such CPath solutions are robust and safe for use in a clinical setting, a critical analysis of their predictive performance and vulnerability to adversarial attacks is required, which is the focus of this paper. Specifically, we show that a highly accurate model for classification of tumour patches in pathology images (AUC > 0.95) can easily be attacked with minimal perturbations which are imperceptible to lay humans and trained pathologists alike. Our analytical results show that it is possible to generate single-instance white-box attacks on specific input images with high success rate and low perturbation energy. Furthermore, we have also generated a single universal perturbation matrix using the training dataset only which, when added to unseen test images, results in forcing the trained neural network to flip its prediction labels with high confidence at a success rate of > 84%. We systematically analyze the relationship between perturbation energy of an adversarial attack, its impact on morphological constructs of clinical significance, their perceptibility by a trained pathologist and saliency maps obtained using deep learning models. Based on our analysis, we strongly recommend that computational pathology models be critically analyzed using the proposed adversarial validation strategy prior to clinical adoption.