 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNine Features in a Random Forest to Learn Taxonomical Semantic Relations
Paper and Code
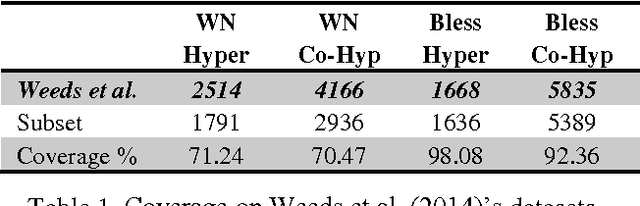
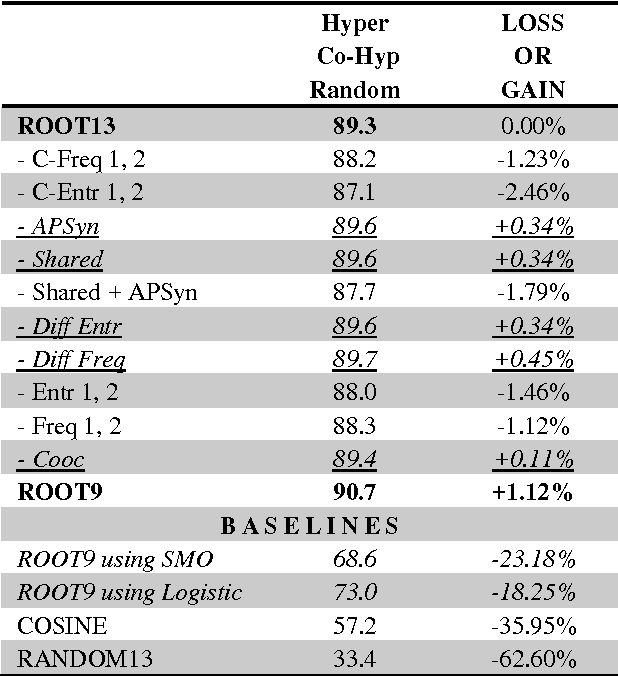
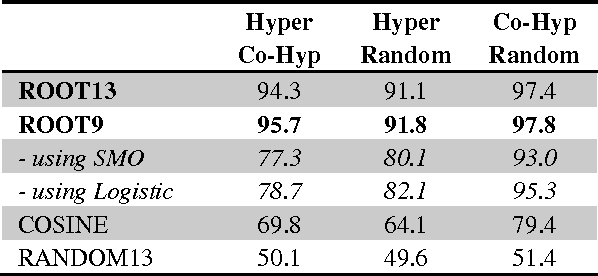

ROOT9 is a supervised system for the classification of hypernyms, co-hyponyms and random words that is derived from the already introduced ROOT13 (Santus et al., 2016). It relies on a Random Forest algorithm and nine unsupervised corpus-based features. We evaluate it with a 10-fold cross validation on 9,600 pairs, equally distributed among the three classes and involving several Parts-Of-Speech (i.e. adjectives, nouns and verbs). When all the classes are present, ROOT9 achieves an F1 score of 90.7%, against a baseline of 57.2% (vector cosine). When the classification is binary, ROOT9 achieves the following results against the baseline: hypernyms-co-hyponyms 95.7% vs. 69.8%, hypernyms-random 91.8% vs. 64.1% and co-hyponyms-random 97.8% vs. 79.4%. In order to compare the performance with the state-of-the-art, we have also evaluated ROOT9 in subsets of the Weeds et al. (2014) datasets, proving that it is in fact competitive. Finally, we investigated whether the system learns the semantic relation or it simply learns the prototypical hypernyms, as claimed by Levy et al. (2015). The second possibility seems to be the most likely, even though ROOT9 can be trained on negative examples (i.e., switched hypernyms) to drastically reduce this bias.