 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNewsQA: A Machine Comprehension Dataset
Paper and Code


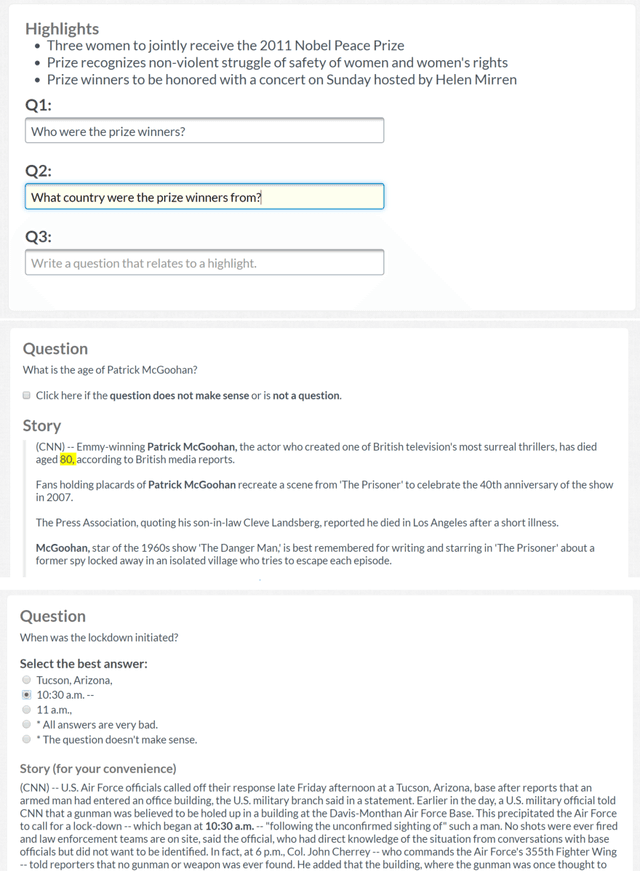
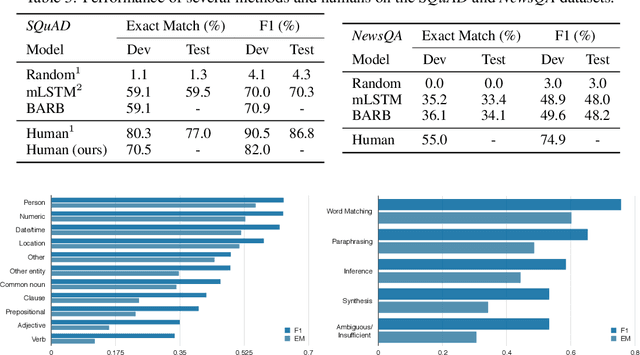
We present NewsQA, a challenging machine comprehension dataset of over 100,000 human-generated question-answer pairs. Crowdworkers supply questions and answers based on a set of over 10,000 news articles from CNN, with answers consisting of spans of text from the corresponding articles. We collect this dataset through a four-stage process designed to solicit exploratory questions that require reasoning. A thorough analysis confirms that NewsQA demands abilities beyond simple word matching and recognizing textual entailment. We measure human performance on the dataset and compare it to several strong neural models. The performance gap between humans and machines (0.198 in F1) indicates that significant progress can be made on NewsQA through future research. The dataset is freely available at https://datasets.maluuba.com/NewsQA.