 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural networks are a priori biased towards Boolean functions with low entropy
Paper and Code
Sep 29, 2019
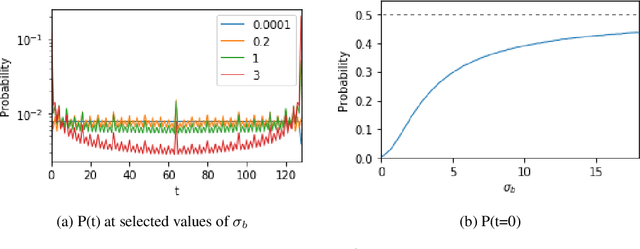
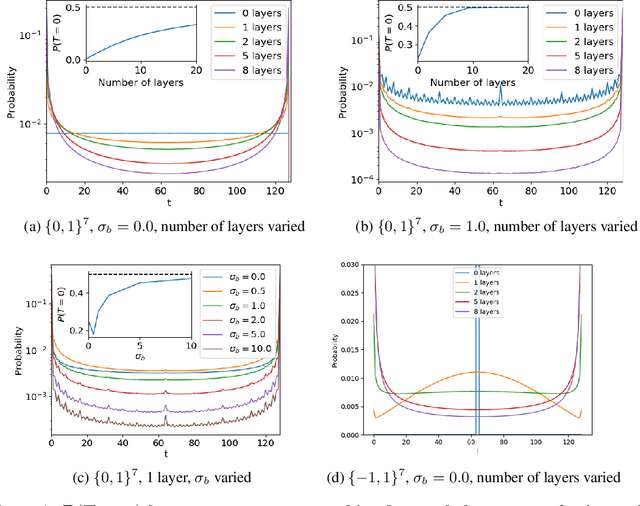
Understanding the inductive bias of neural networks is critical to explaining their ability to generalise. Here, for one of the simplest neural networks -- a single-layer perceptron with $n$ input neurons, one output neuron, and no threshold bias term -- we prove that upon random initialisation of weights, the a priori probability $P(t)$ that it represents a Boolean function that classifies $t$ points in $\{0,1\}^n$ as $1$ has a remarkably simple form: $ P(t) = 2^{-n} \,\, {\rm for} \,\, 0\leq t < 2^n$. Since a perceptron can express far fewer Boolean functions with small or large values of $t$ (low "entropy") than with intermediate values of $t$ (high "entropy") there is, on average, a strong intrinsic a-priori bias towards individual functions with low entropy. Furthermore, within a class of functions with fixed $t$, we often observe a further intrinsic bias towards functions of lower complexity. Finally, we prove that, regardless of the distribution of inputs, the bias towards low entropy becomes monotonically stronger upon adding ReLU layers, and empirically show that increasing the variance of the bias term has a similar effect.