 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network Compatible Off-Policy Natural Actor-Critic Algorithm
Paper and Code
Oct 19, 2021
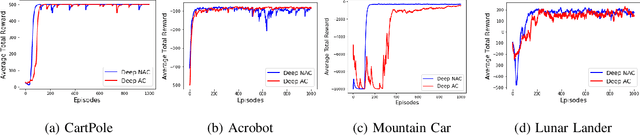
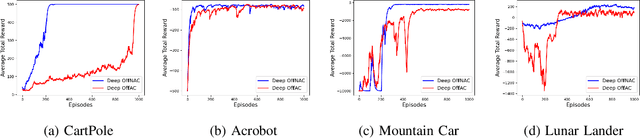
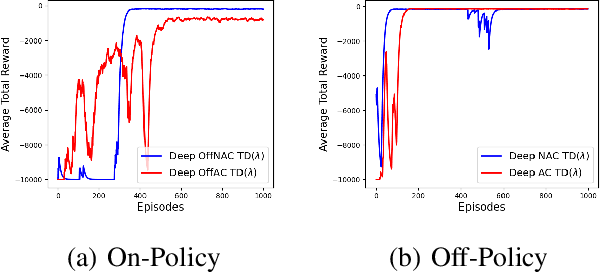
Learning optimal behavior from existing data is one of the most important problems in Reinforcement Learning (RL). This is known as "off-policy control" in RL where an agent's objective is to compute an optimal policy based on the data obtained from the given policy (known as the behavior policy). As the optimal policy can be very different from the behavior policy, learning optimal behavior is very hard in the "off-policy" setting compared to the "on-policy" setting where new data from the policy updates will be utilized in learning. This work proposes an off-policy natural actor-critic algorithm that utilizes state-action distribution correction for handling the off-policy behavior and the natural policy gradient for sample efficiency. The existing natural gradient-based actor-critic algorithms with convergence guarantees require fixed features for approximating both policy and value functions. This often leads to sub-optimal learning in many RL applications. On the other hand, our proposed algorithm utilizes compatible features that enable one to use arbitrary neural networks to approximate the policy and the value function and guarantee convergence to a locally optimal policy. We illustrate the benefit of the proposed off-policy natural gradient algorithm by comparing it with the vanilla gradient actor-critic algorithm on benchmark RL tasks.