 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Machine Translation with Joint Representation
Paper and Code


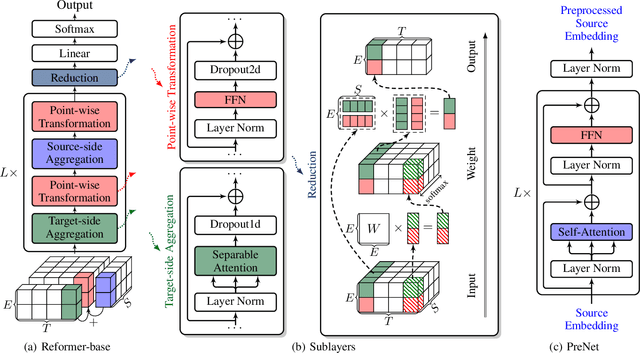

Though early successes of Statistical Machine Translation (SMT) systems are attributed in part to the explicit modelling of the interaction between any two source and target units, e.g., alignment, the recent Neural Machine Translation (NMT) systems resort to the attention which partially encodes the interaction for efficiency. In this paper, we employ Joint Representation that fully accounts for each possible interaction. We sidestep the inefficiency issue by refining representations with the proposed efficient attention operation. The resulting Reformer models offer a new Sequence-to- Sequence modelling paradigm besides the Encoder-Decoder framework and outperform the Transformer baseline in either the small scale IWSLT14 German-English, English-German and IWSLT15 Vietnamese-English or the large scale NIST12 Chinese-English translation tasks by about 1 BLEU point.We also propose a systematic model scaling approach, allowing the Reformer model to beat the state-of-the-art Transformer in IWSLT14 German-English and NIST12 Chinese-English with about 50% fewer parameters. The code is publicly available at https://github.com/lyy1994/reformer.