 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Descent for Visual 3D Human Pose and Shape
Paper and Code
Aug 16, 2020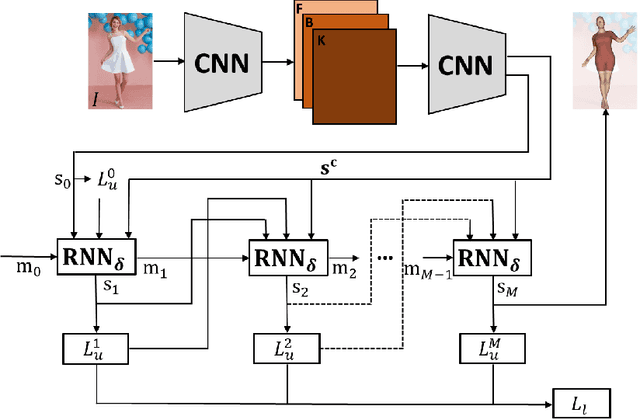
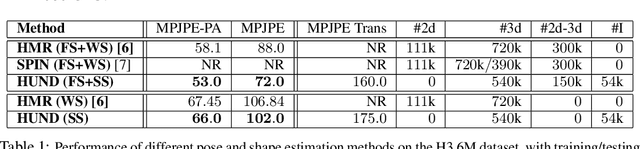

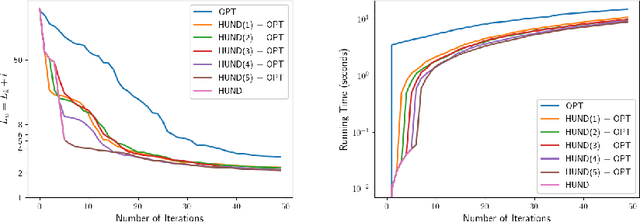
We present deep neural network methodology to reconstruct the 3d pose and shape of people, given an input RGB image. We rely on a recently introduced, expressivefull body statistical 3d human model, GHUM, trained end-to-end, and learn to reconstruct its pose and shape state in a self-supervised regime. Central to our methodology, is a learning to learn and optimize approach, referred to as HUmanNeural Descent (HUND), which avoids both second-order differentiation when training the model parameters,and expensive state gradient descent in order to accurately minimize a semantic differentiable rendering loss at test time. Instead, we rely on novel recurrent stages to update the pose and shape parameters such that not only losses are minimized effectively, but the process is meta-regularized in order to ensure end-progress. HUND's symmetry between training and testing makes it the first 3d human sensing architecture to natively support different operating regimes including self-supervised ones. In diverse tests, we show that HUND achieves very competitive results in datasets like H3.6M and 3DPW, aswell as good quality 3d reconstructions for complex imagery collected in-the-wild.