 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearly Dimension-Independent Sparse Linear Bandit over Small Action Spaces via Best Subset Selection
Paper and Code
Sep 04, 2020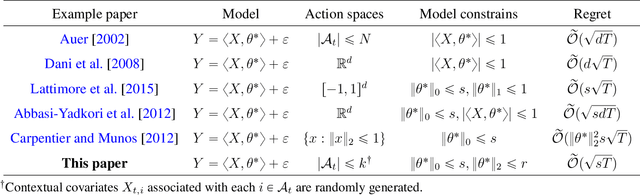


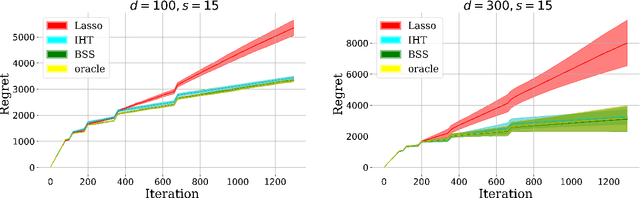
We consider the stochastic contextual bandit problem under the high dimensional linear model. We focus on the case where the action space is finite and random, with each action associated with a randomly generated contextual covariate. This setting finds essential applications such as personalized recommendation, online advertisement, and personalized medicine. However, it is very challenging as we need to balance exploration and exploitation. We propose doubly growing epochs and estimating the parameter using the best subset selection method, which is easy to implement in practice. This approach achieves $ \tilde{\mathcal{O}}(s\sqrt{T})$ regret with high probability, which is nearly independent in the ``ambient'' regression model dimension $d$. We further attain a sharper $\tilde{\mathcal{O}}(\sqrt{sT})$ regret by using the \textsc{SupLinUCB} framework and match the minimax lower bound of low-dimensional linear stochastic bandit problems. Finally, we conduct extensive numerical experiments to demonstrate the applicability and robustness of our algorithms empirically.