 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultinomial Distribution Learning for Effective Neural Architecture Search
Paper and Code
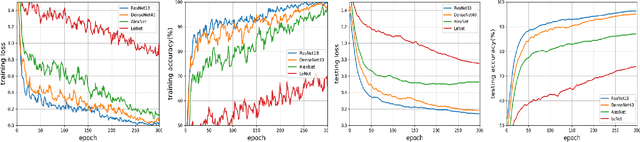
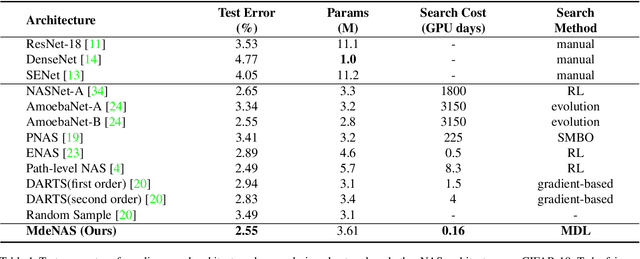
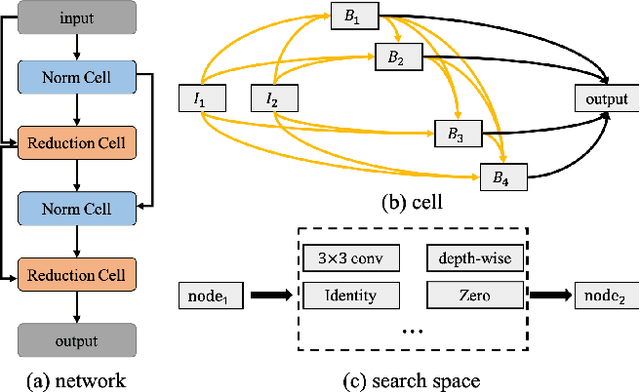
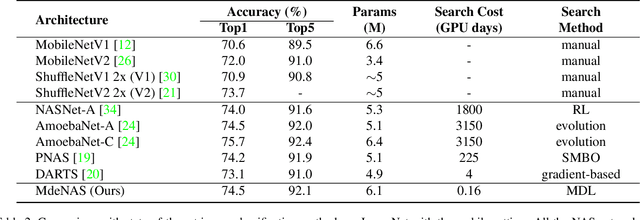
Architectures obtained by Neural Architecture Search (NAS) have achieved highly competitive performance in various computer vision tasks. However, the prohibitive computation demand of forward-backward propagation in deep neural networks and searching algorithms makes it difficult to apply NAS in practice. In this paper, we propose a Multinomial Distribution Learning for extremely effective NAS, which considers the search space as a joint multinomial distribution, i.e., the operation between two nodes is sampled from this distribution, and the optimal network structure is obtained by the operations with the most likely probability in this distribution. Therefore, NAS can be transformed to a multinomial distribution learning problem, i.e., the distribution is optimized to have high expectation of the performance. Besides, a hypothesis that the performance ranking is consistent in every training epoch is proposed and demonstrated to further accelerate the learning process. Experiments on CIFAR-10 and ImageNet demonstrate the effectiveness of our method. On CIFAR-10, the structure searched by our method achieves 2.4\% test error, while being 6.0 $\times$ (only 4 GPU hours on GTX1080Ti) faster compared with state-of-the-art NAS algorithms. On ImageNet, our model achieves 75.2\% top-1 accuracy under MobileNet settings (MobileNet V1/V2), while being 1.2$\times$ faster with measured GPU latency. Test code is available at https://github.com/tanglang96/MDENAS