 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Simplification of Medical Texts
Paper and Code



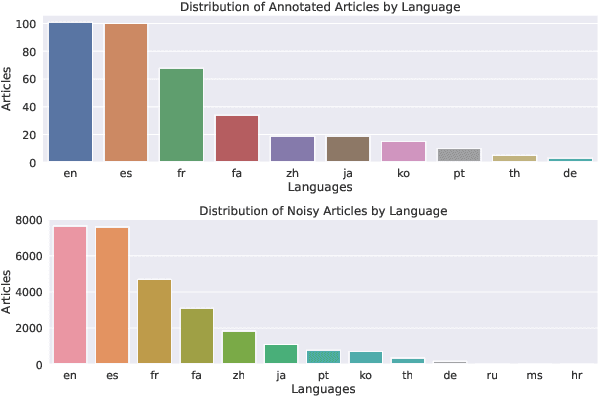
Automated text simplification aims to produce simple versions of complex texts. This task is especially useful in the medical domain, where the latest medical findings are typically communicated via complex and technical articles. This creates barriers for laypeople seeking access to up-to-date medical findings, consequently impeding progress on health literacy. Most existing work on medical text simplification has focused on monolingual settings, with the result that such evidence would be available only in just one language (most often, English). This work addresses this limitation via multilingual simplification, i.e., directly simplifying complex texts into simplified texts in multiple languages. We introduce MultiCochrane, the first sentence-aligned multilingual text simplification dataset for the medical domain in four languages: English, Spanish, French, and Farsi. We evaluate fine-tuned and zero-shot models across these languages, with extensive human assessments and analyses. Although models can now generate viable simplified texts, we identify outstanding challenges that this dataset might be used to address.