 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Adaptive Fusion Network for 3D Object Detection
Paper and Code
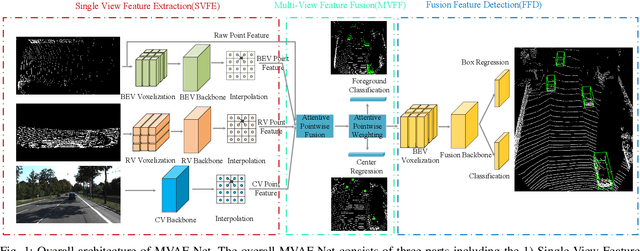

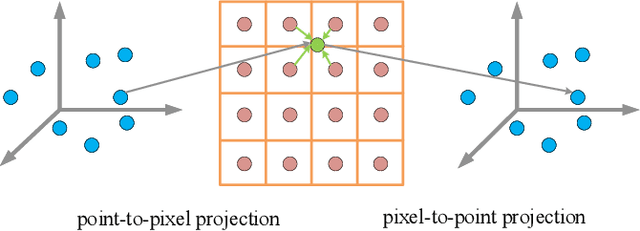
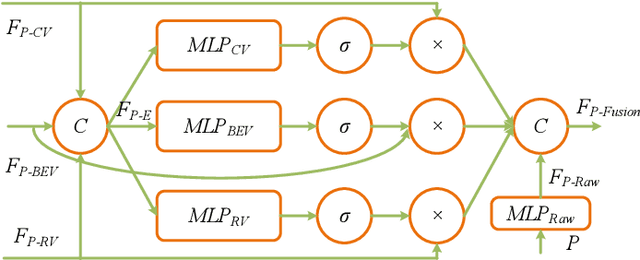
3D object detection based on LiDAR-camera fusion is becoming an emerging research theme for autonomous driving. However, it has been surprisingly difficult to effectively fuse both modalities without information loss and interference. To solve this issue, we propose a single-stage multi-view fusion framework that takes LiDAR Birds-Eye View, LiDAR Range View and Camera View images as inputs for 3D object detection. To effectively fuse multi-view features, we propose an Attentive Pointwise Fusion (APF) module to estimate the importance of the three sources with attention mechanisms which can achieve adaptive fusion of multi-view features in a pointwise manner. Besides, an Attentive Pointwise Weighting (APW) module is designed to help the network learn structure information and point feature importance with two extra tasks: foreground classification and center regression, and the predicted foreground probability will be used to reweight the point features. We design an end-to-end learnable network named MVAF-Net to integrate these two components. Our evaluations conducted on the KITTI 3D object detection datasets demonstrate that the proposed APF and APW module offer significant performance gain and that the proposed MVAF-Net achieves state-of-the-art performance in the KITTI benchmark.