 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Teacher Knowledge Distillation for Incremental Implicitly-Refined Classification
Paper and Code
Feb 24, 2022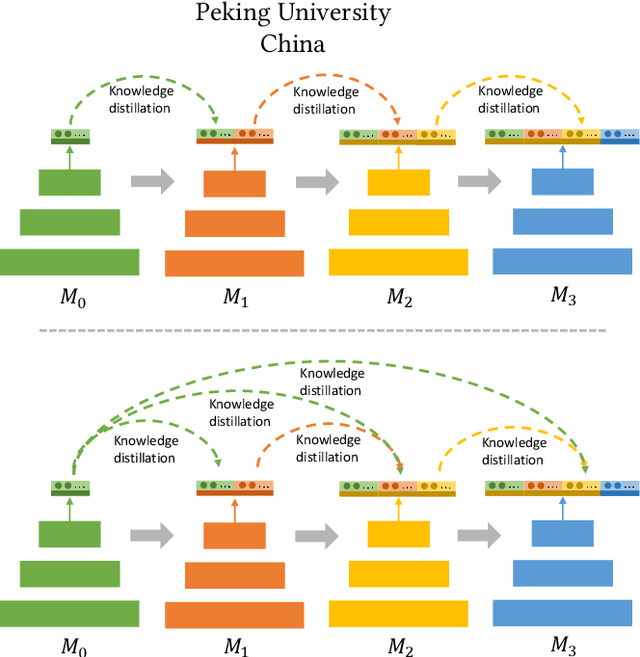
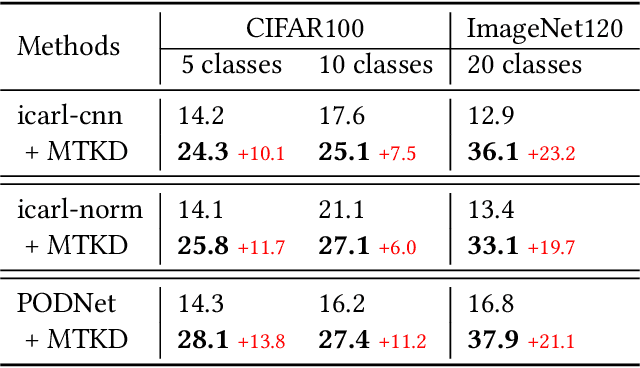
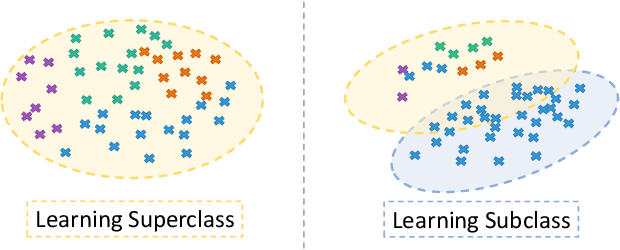

Incremental learning methods can learn new classes continually by distilling knowledge from the last model (as a teacher model) to the current model (as a student model) in the sequentially learning process. However, these methods cannot work for Incremental Implicitly-Refined Classification (IIRC), an incremental learning extension where the incoming classes could have two granularity levels, a superclass label and a subclass label. This is because the previously learned superclass knowledge may be occupied by the subclass knowledge learned sequentially. To solve this problem, we propose a novel Multi-Teacher Knowledge Distillation (MTKD) strategy. To preserve the subclass knowledge, we use the last model as a general teacher to distill the previous knowledge for the student model. To preserve the superclass knowledge, we use the initial model as a superclass teacher to distill the superclass knowledge as the initial model contains abundant superclass knowledge. However, distilling knowledge from two teacher models could result in the student model making some redundant predictions. We further propose a post-processing mechanism, called as Top-k prediction restriction to reduce the redundant predictions. Our experimental results on IIRC-ImageNet120 and IIRC-CIFAR100 show that the proposed method can achieve better classification accuracy compared with existing state-of-the-art methods.