 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Speaker Multi-Lingual VQTTS System for LIMMITS 2023 Challenge
Paper and Code
Apr 25, 2023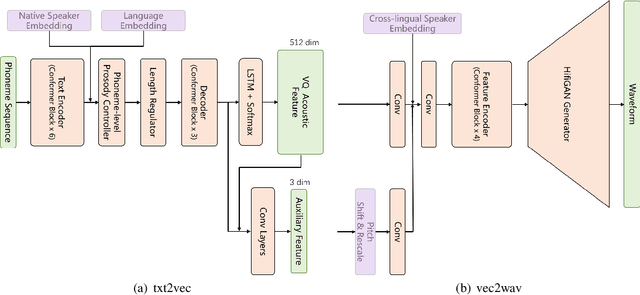

In this paper, we describe the systems developed by the SJTU X-LANCE team for LIMMITS 2023 Challenge, and we mainly focus on the winning system on naturalness for track 1. The aim of this challenge is to build a multi-speaker multi-lingual text-to-speech (TTS) system for Marathi, Hindi and Telugu. Each of the languages has a male and a female speaker in the given dataset. In track 1, only 5 hours data from each speaker can be selected to train the TTS model. Our system is based on the recently proposed VQTTS that utilizes VQ acoustic feature rather than mel-spectrogram. We introduce additional speaker embeddings and language embeddings to VQTTS for controlling the speaker and language information. In the cross-lingual evaluations where we need to synthesize speech in a cross-lingual speaker's voice, we provide a native speaker's embedding to the acoustic model and the target speaker's embedding to the vocoder. In the subjective MOS listening test on naturalness, our system achieves 4.77 which ranks first.