 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti network InfoMax: A pre-training method involving graph convolutional networks
Paper and Code
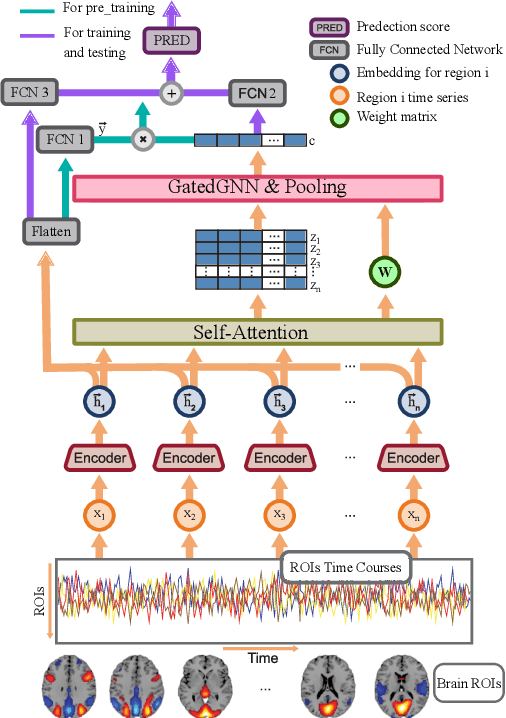
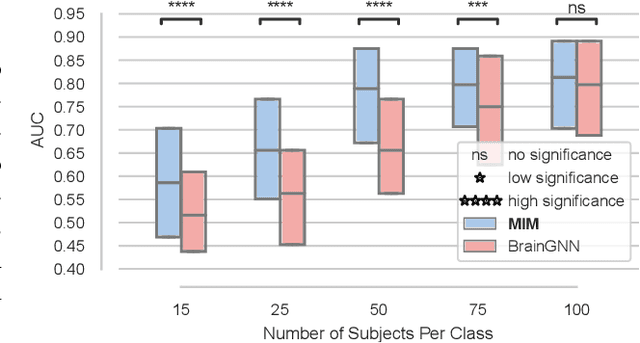
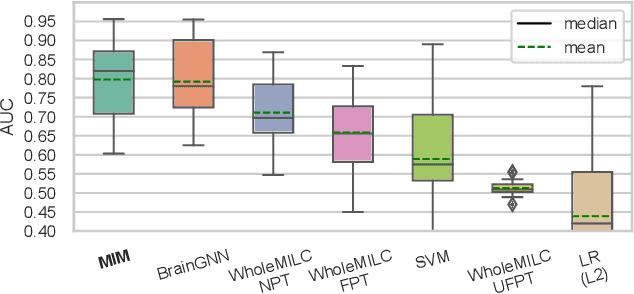
Discovering distinct features and their relations from data can help us uncover valuable knowledge crucial for various tasks, e.g., classification. In neuroimaging, these features could help to understand, classify, and possibly prevent brain disorders. Model introspection of highly performant overparameterized deep learning (DL) models could help find these features and relations. However, to achieve high-performance level DL models require numerous labeled training samples ($n$) rarely available in many fields. This paper presents a pre-training method involving graph convolutional/neural networks (GCNs/GNNs), based on maximizing mutual information between two high-level embeddings of an input sample. Many of the recently proposed pre-training methods pre-train one of many possible networks of an architecture. Since almost every DL model is an ensemble of multiple networks, we take our high-level embeddings from two different networks of a model --a convolutional and a graph network--. The learned high-level graph latent representations help increase performance for downstream graph classification tasks and bypass the need for a high number of labeled data samples. We apply our method to a neuroimaging dataset for classifying subjects into healthy control (HC) and schizophrenia (SZ) groups. Our experiments show that the pre-trained model significantly outperforms the non-pre-trained model and requires $50\%$ less data for similar performance.