Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Simultaneous Forecasting of Vehicle Position Sequences using Social Attention
Paper and Code
Oct 08, 2019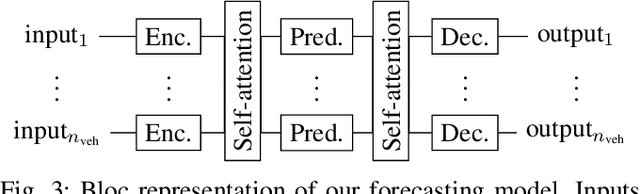
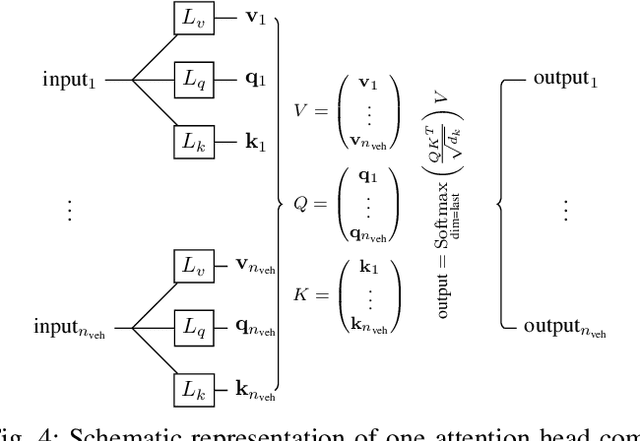


Vehicle trajectory forecasting models use a wide variety of frameworks for interaction and multi-modality. They rely on various representations of the road scene and definitions of maneuvers. In this paper we present a simple model that simultaneously forecasts each vehicle position on a road scene as a sequence of multi-modal probability density functions. This relies solely on vehicle position tracks and does not define maneuvers. We produce an easily extendable model that combines these predictive capabilities while surpassing state-of-the-art results. Its architecture uses multi-head attention to account for complete interactions between all vehicles, and long short-term memory (LSTM) layers for encoding and forecasting.
* 7 pages, 6 figures, under review at ICRA
View paper on