 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Interaction Graph Convolutional Network for Temporal Language Localization in Videos
Paper and Code
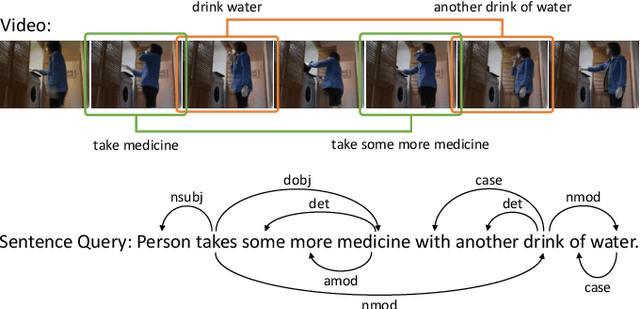
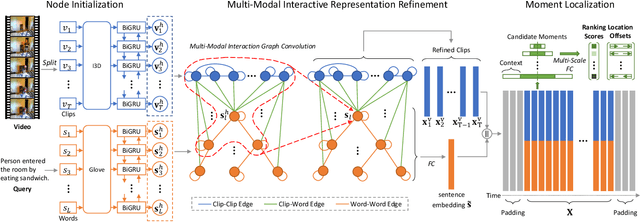
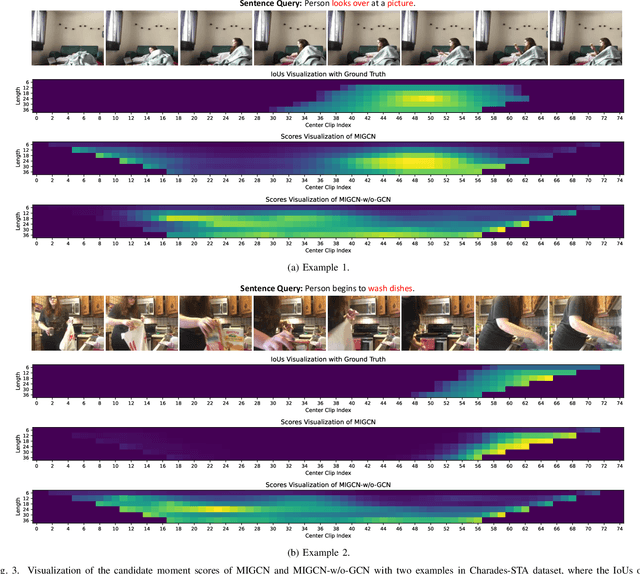

This paper focuses on tackling the problem of temporal language localization in videos, which aims to identify the start and end points of a moment described by a natural language sentence in an untrimmed video. However, it is non-trivial since it requires not only the comprehensive understanding of the video and sentence query, but also the accurate semantic correspondence capture between them. Existing efforts are mainly centered on exploring the sequential relation among video clips and query words to reason the video and sentence query, neglecting the other intra-modal relations (e.g., semantic similarity among video clips and syntactic dependency among the query words). Towards this end, in this work, we propose a Multi-modal Interaction Graph Convolutional Network (MIGCN), which jointly explores the complex intra-modal relations and inter-modal interactions residing in the video and sentence query to facilitate the understanding and semantic correspondence capture of the video and sentence query. In addition, we devise an adaptive context-aware localization method, where the context information is taken into the candidate moments and the multi-scale fully connected layers are designed to rank and adjust the boundary of the generated coarse candidate moments with different lengths. Extensive experiments on Charades-STA and ActivityNet datasets demonstrate the promising performance and superior efficiency of our model.