 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRTNet: Multi-Resolution Temporal Network for Video Sentence Grounding
Paper and Code
Dec 27, 2022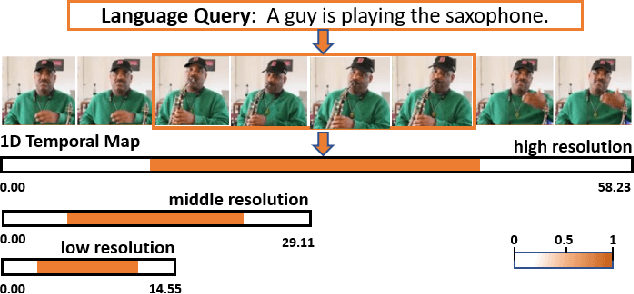



Given an untrimmed video and natural language query, video sentence grounding aims to localize the target temporal moment in the video. Existing methods mainly tackle this task by matching and aligning semantics of the descriptive sentence and video segments on a single temporal resolution, while neglecting the temporal consistency of video content in different resolutions. In this work, we propose a novel multi-resolution temporal video sentence grounding network: MRTNet, which consists of a multi-modal feature encoder, a Multi-Resolution Temporal (MRT) module, and a predictor module. MRT module is an encoder-decoder network, and output features in the decoder part are in conjunction with Transformers to predict the final start and end timestamps. Particularly, our MRT module is hot-pluggable, which means it can be seamlessly incorporated into any anchor-free models. Besides, we utilize a hybrid loss to supervise cross-modal features in MRT module for more accurate grounding in three scales: frame-level, clip-level and sequence-level. Extensive experiments on three prevalent datasets have shown the effectiveness of MRTNet.