 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOORe: Model-based Offline-to-Online Reinforcement Learning
Paper and Code
Jan 25, 2022

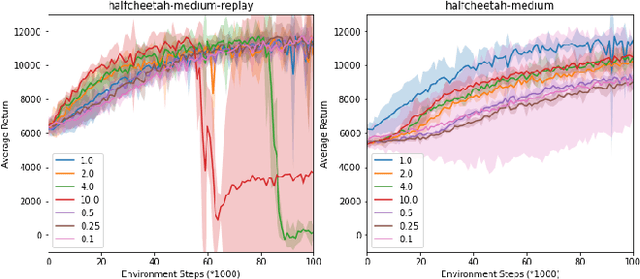
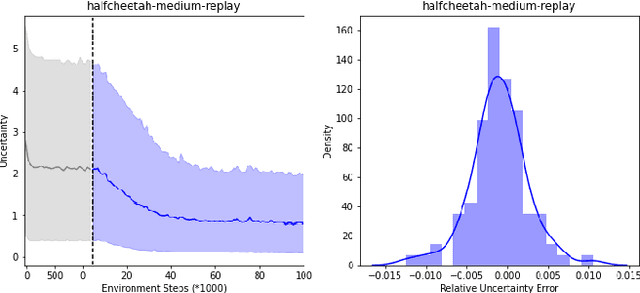
With the success of offline reinforcement learning (RL), offline trained RL policies have the potential to be further improved when deployed online. A smooth transfer of the policy matters in safe real-world deployment. Besides, fast adaptation of the policy plays a vital role in practical online performance improvement. To tackle these challenges, we propose a simple yet efficient algorithm, Model-based Offline-to-Online Reinforcement learning (MOORe), which employs a prioritized sampling scheme that can dynamically adjust the offline and online data for smooth and efficient online adaptation of the policy. We provide a theoretical foundation for our algorithms design. Experiment results on the D4RL benchmark show that our algorithm smoothly transfers from offline to online stages while enabling sample-efficient online adaption, and also significantly outperforms existing methods.