 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMomentum-Based Federated Reinforcement Learning with Interaction and Communication Efficiency
Paper and Code
May 29, 2024
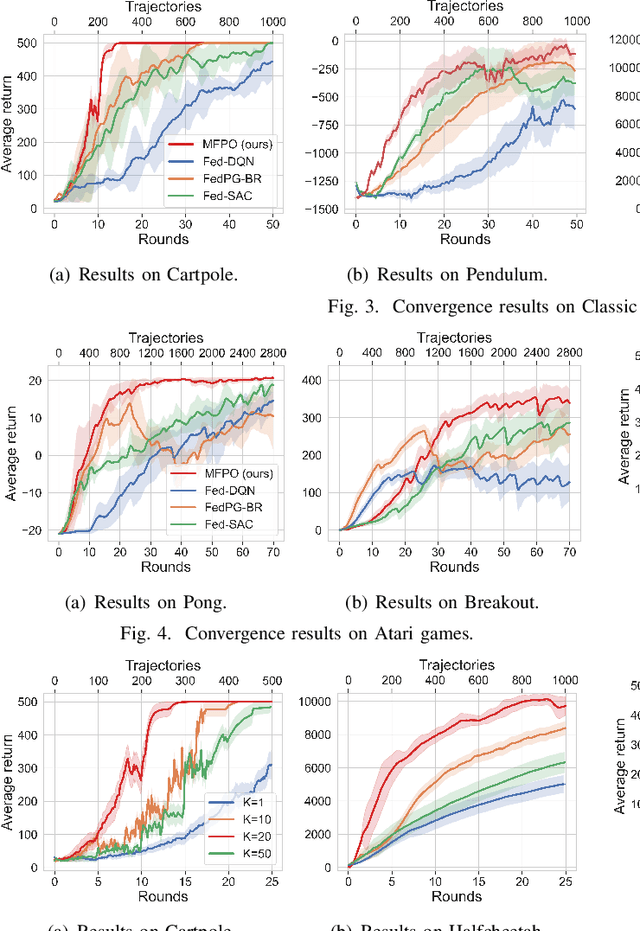
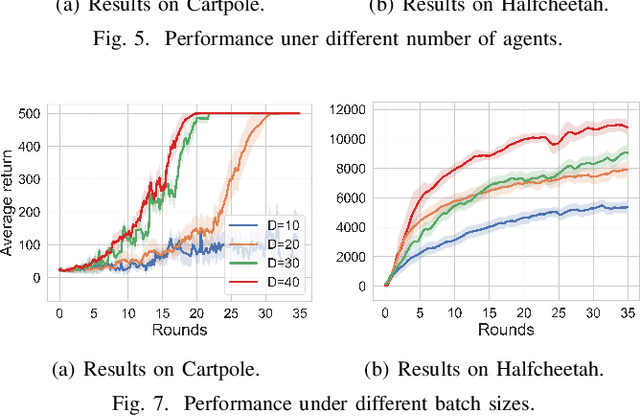
Federated Reinforcement Learning (FRL) has garnered increasing attention recently. However, due to the intrinsic spatio-temporal non-stationarity of data distributions, the current approaches typically suffer from high interaction and communication costs. In this paper, we introduce a new FRL algorithm, named $\texttt{MFPO}$, that utilizes momentum, importance sampling, and additional server-side adjustment to control the shift of stochastic policy gradients and enhance the efficiency of data utilization. We prove that by proper selection of momentum parameters and interaction frequency, $\texttt{MFPO}$ can achieve $\tilde{\mathcal{O}}(H N^{-1}\epsilon^{-3/2})$ and $\tilde{\mathcal{O}}(\epsilon^{-1})$ interaction and communication complexities ($N$ represents the number of agents), where the interaction complexity achieves linear speedup with the number of agents, and the communication complexity aligns the best achievable of existing first-order FL algorithms. Extensive experiments corroborate the substantial performance gains of $\texttt{MFPO}$ over existing methods on a suite of complex and high-dimensional benchmarks.