 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolecular Language Model as Multi-task Generator
Paper and Code
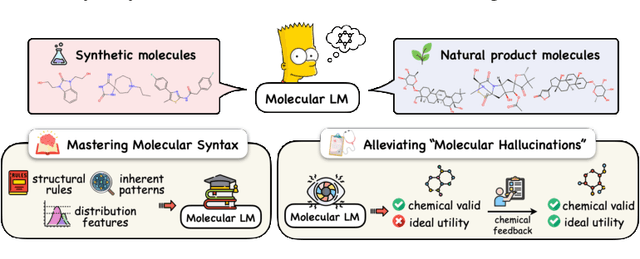
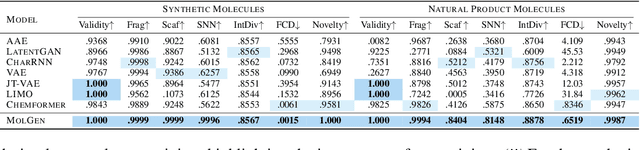
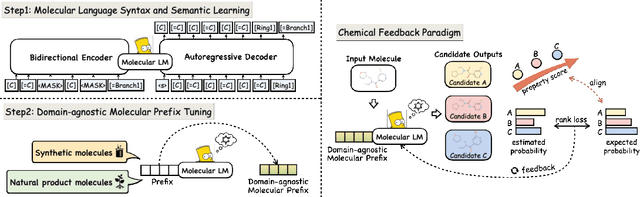
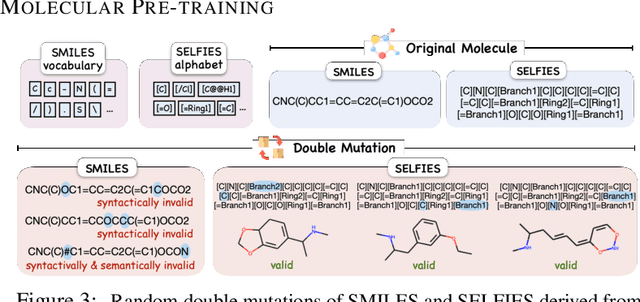
Molecule generation with desired properties has grown immensely in popularity by disruptively changing the way scientists design molecular structures and providing support for chemical and materials design. However, despite the promising outcome, previous machine learning-based deep generative models suffer from a reliance on complex, task-specific fine-tuning, limited dimensional latent spaces, or the quality of expert rules. In this work, we propose MolGen, a pre-trained molecular language model that effectively learns and shares knowledge across multiple generation tasks and domains. Specifically, we pre-train MolGen with the chemical language SELFIES on more than 100 million unlabelled molecules. We further propose multi-task molecular prefix tuning across several molecular generation tasks and different molecular domains (synthetic & natural products) with a self-feedback mechanism. Extensive experiments show that MolGen can obtain superior performances on well-known molecular generation benchmark datasets. The further analysis illustrates that MolGen can accurately capture the distribution of molecules, implicitly learn their structural characteristics, and efficiently explore the chemical space with the guidance of multi-task molecular prefix tuning. Codes, datasets, and the pre-trained model will be available in https://github.com/zjunlp/MolGen.