 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Techniques for Machine Learning Fairness: A Survey
Paper and Code
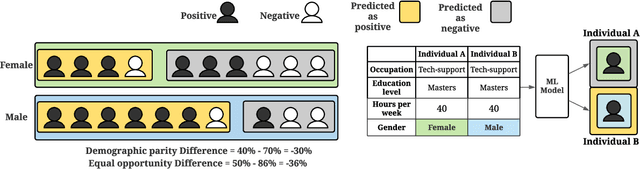
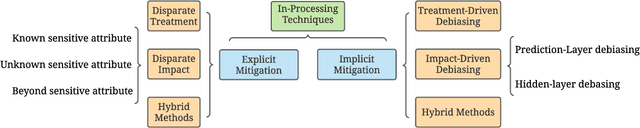
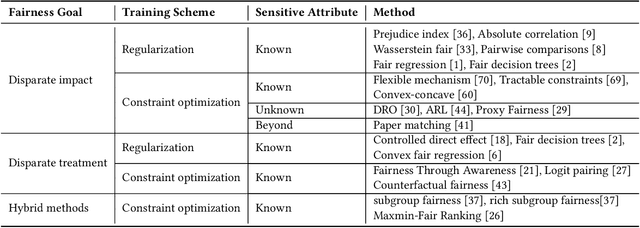
Machine learning models are becoming pervasive in high-stakes applications. Despite their clear benefits in terms of performance, the models could show bias against minority groups and result in fairness issues in a decision-making process, leading to severe negative impacts on the individuals and the society. In recent years, various techniques have been developed to mitigate the bias for machine learning models. Among them, in-processing methods have drawn increasing attention from the community, where fairness is directly taken into consideration during model design to induce intrinsically fair models and fundamentally mitigate fairness issues in outputs and representations. In this survey, we review the current progress of in-processing bias mitigation techniques. Based on where the fairness is achieved in the model, we categorize them into explicit and implicit methods, where the former directly incorporates fairness metrics in training objectives, and the latter focuses on refining latent representation learning. Finally, we conclude the survey with a discussion of the research challenges in this community to motivate future exploration.