 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-free Reinforcement Learning in Infinite-horizon Average-reward Markov Decision Processes
Paper and Code
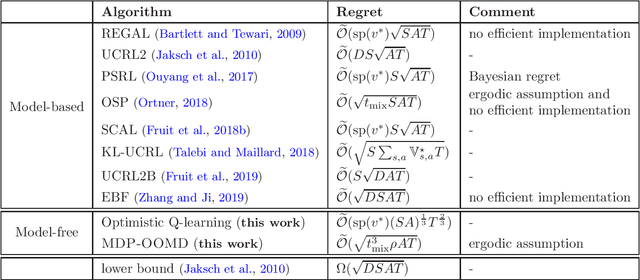
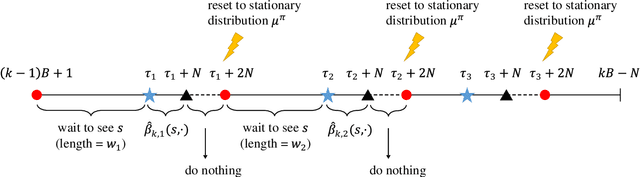
Model-free reinforcement learning is known to be memory and computation efficient and more amendable to large scale problems. In this paper, two model-free algorithms are introduced for learning infinite-horizon average-reward Markov Decision Processes (MDPs). The first algorithm reduces the problem to the discounted-reward version and achieves $\mathcal{O}(T^{2/3})$ regret after $T$ steps, under the minimal assumption of weakly communicating MDPs. The second algorithm makes use of recent advances in adaptive algorithms for adversarial multi-armed bandits and improves the regret to $\mathcal{O}(\sqrt{T})$, albeit with a stronger ergodic assumption. To the best of our knowledge, these are the first model-free algorithms with sub-linear regret (that is polynomial in all parameters) in the infinite-horizon average-reward setting.