 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMix Dimension in Poincaré Geometry for 3D Skeleton-based Action Recognition
Paper and Code
Aug 03, 2020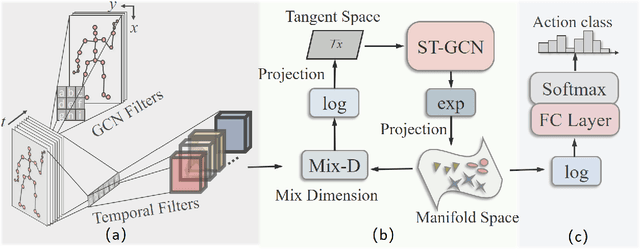

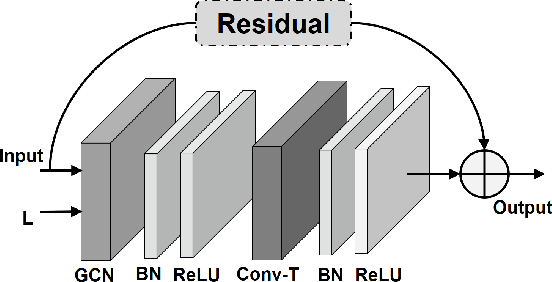
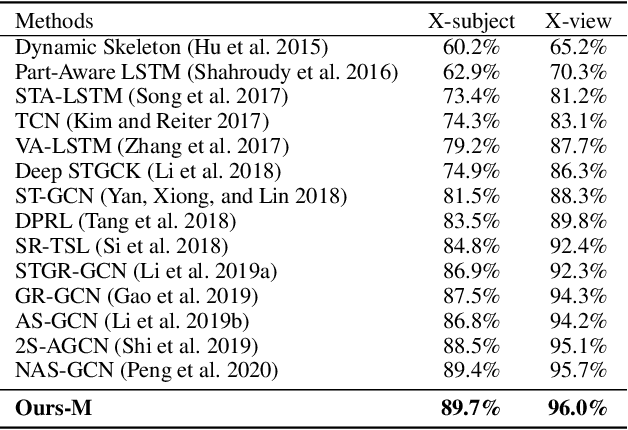
Graph Convolutional Networks (GCNs) have already demonstrated their powerful ability to model the irregular data, e.g., skeletal data in human action recognition, providing an exciting new way to fuse rich structural information for nodes residing in different parts of a graph. In human action recognition, current works introduce a dynamic graph generation mechanism to better capture the underlying semantic skeleton connections and thus improves the performance. In this paper, we provide an orthogonal way to explore the underlying connections. Instead of introducing an expensive dynamic graph generation paradigm, we build a more efficient GCN on a Riemann manifold, which we think is a more suitable space to model the graph data, to make the extracted representations fit the embedding matrix. Specifically, we present a novel spatial-temporal GCN (ST-GCN) architecture which is defined via the Poincar\'e geometry such that it is able to better model the latent anatomy of the structure data. To further explore the optimal projection dimension in the Riemann space, we mix different dimensions on the manifold and provide an efficient way to explore the dimension for each ST-GCN layer. With the final resulted architecture, we evaluate our method on two current largest scale 3D datasets, i.e., NTU RGB+D and NTU RGB+D 120. The comparison results show that the model could achieve a superior performance under any given evaluation metrics with only 40\% model size when compared with the previous best GCN method, which proves the effectiveness of our model.