 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMirror Descent Maximizes Generalized Margin and Can Be Implemented Efficiently
Paper and Code

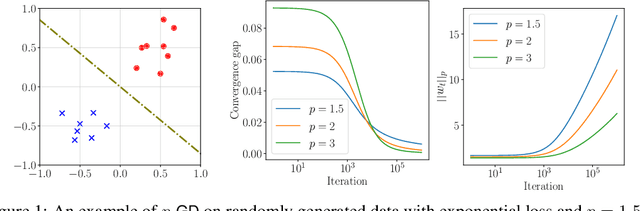

Driven by the empirical success and wide use of deep neural networks, understanding the generalization performance of overparameterized models has become an increasingly popular question. To this end, there has been substantial effort to characterize the implicit bias of the optimization algorithms used, such as gradient descent (GD), and the structural properties of their preferred solutions. This paper answers an open question in this literature: For the classification setting, what solution does mirror descent (MD) converge to? Specifically, motivated by its efficient implementation, we consider the family of mirror descent algorithms with potential function chosen as the $p$-th power of the $\ell_p$-norm, which is an important generalization of GD. We call this algorithm $p$-$\textsf{GD}$. For this family, we characterize the solutions it obtains and show that it converges in direction to a generalized maximum-margin solution with respect to the $\ell_p$-norm for linearly separable classification. While the MD update rule is in general expensive to compute and perhaps not suitable for deep learning, $p$-$\textsf{GD}$ is fully parallelizable in the same manner as SGD and can be used to train deep neural networks with virtually no additional computational overhead. Using comprehensive experiments with both linear and deep neural network models, we demonstrate that $p$-$\textsf{GD}$ can noticeably affect the structure and the generalization performance of the learned models.