 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniVLM: A Smaller and Faster Vision-Language Model
Paper and Code
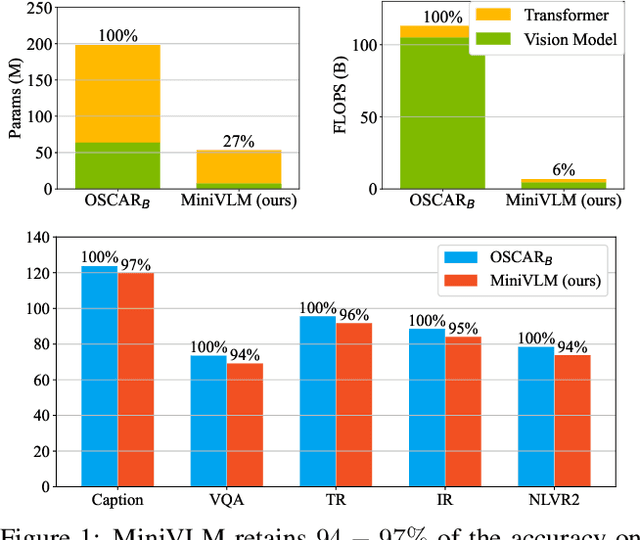

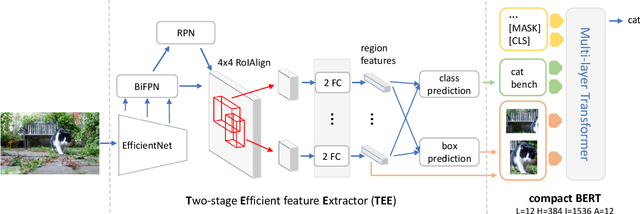

Recent vision-language (VL) studies have shown remarkable progress by learning generic representations from massive image-text pairs with transformer models and then fine-tuning on downstream VL tasks. While existing research has been focused on achieving high accuracy with large pre-trained models, building a lightweight model is of great value in practice but is less explored. In this paper, we propose a smaller and faster VL model, MiniVLM, which can be finetuned with good performance on various downstream tasks like its larger counterpart. MiniVLM consists of two modules, a vision feature extractor and a transformer-based vision-language fusion module. We design a Two-stage Efficient feature Extractor (TEE), inspired by the one-stage EfficientDet network, to significantly reduce the time cost of visual feature extraction by $95\%$, compared to a baseline model. We adopt the MiniLM structure to reduce the computation cost of the transformer module after comparing different compact BERT models. In addition, we improve the MiniVLM pre-training by adding $7M$ Open Images data, which are pseudo-labeled by a state-of-the-art captioning model. We also pre-train with high-quality image tags obtained from a strong tagging model to enhance cross-modality alignment. The large models are used offline without adding any overhead in fine-tuning and inference. With the above design choices, our MiniVLM reduces the model size by $73\%$ and the inference time cost by $94\%$ while being able to retain $94-97\%$ of the accuracy on multiple VL tasks. We hope that MiniVLM helps ease the use of the state-of-the-art VL research for on-the-edge applications.