Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMini-Batch Primal and Dual Methods for SVMs
Paper and Code
Mar 10, 2013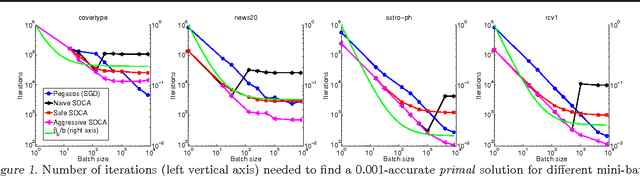


We address the issue of using mini-batches in stochastic optimization of SVMs. We show that the same quantity, the spectral norm of the data, controls the parallelization speedup obtained for both primal stochastic subgradient descent (SGD) and stochastic dual coordinate ascent (SCDA) methods and use it to derive novel variants of mini-batched SDCA. Our guarantees for both methods are expressed in terms of the original nonsmooth primal problem based on the hinge-loss.
View paper on