Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMin Max Generalization for Two-stage Deterministic Batch Mode Reinforcement Learning: Relaxation Schemes
Paper and Code
Oct 30, 2012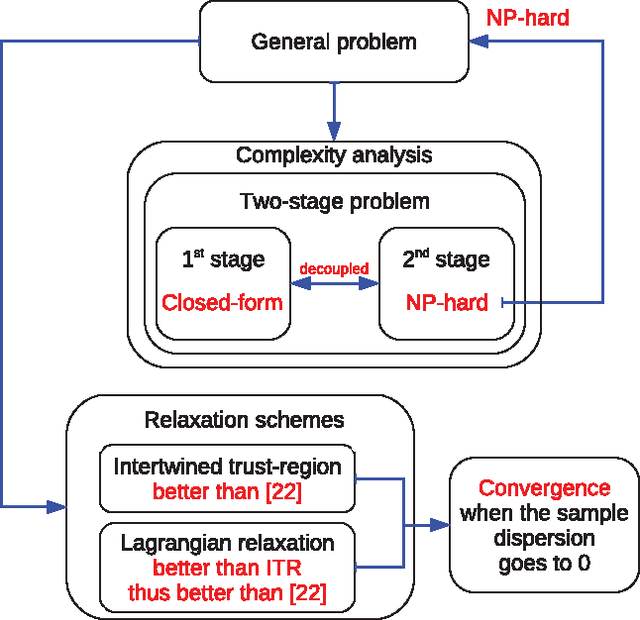
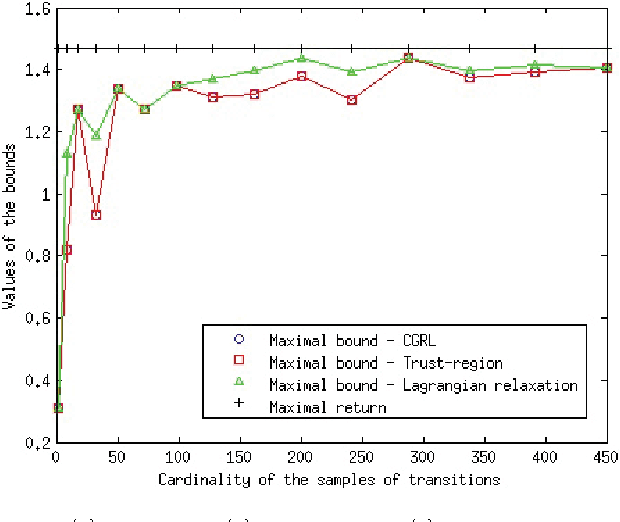
We study the minmax optimization problem introduced in [22] for computing policies for batch mode reinforcement learning in a deterministic setting. First, we show that this problem is NP-hard. In the two-stage case, we provide two relaxation schemes. The first relaxation scheme works by dropping some constraints in order to obtain a problem that is solvable in polynomial time. The second relaxation scheme, based on a Lagrangian relaxation where all constraints are dualized, leads to a conic quadratic programming problem. We also theoretically prove and empirically illustrate that both relaxation schemes provide better results than those given in [22].
View paper on