 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMFFCN: Multi-layer Feature Fusion Convolution Network for Audio-visual Speech Enhancement
Paper and Code
Feb 04, 2021
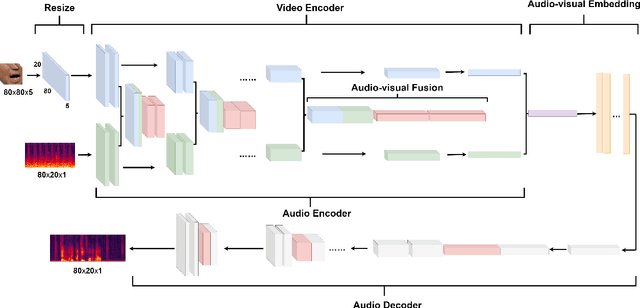
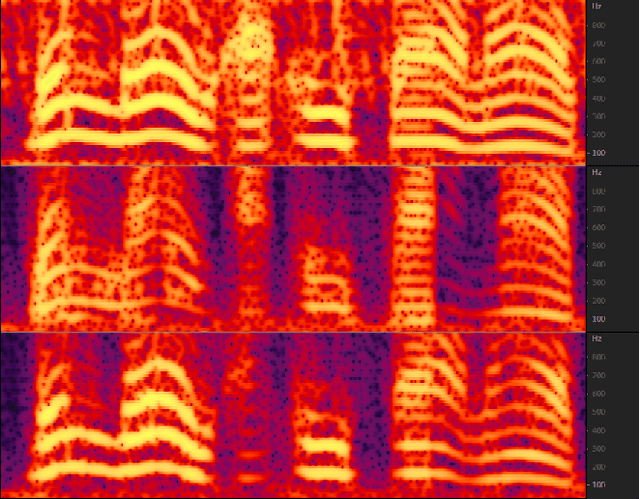
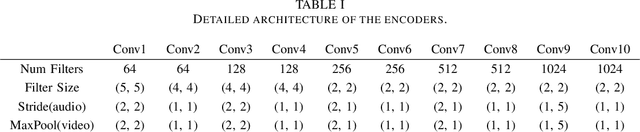
The purpose of speech enhancement is to extract target speech signal from a mixture of sounds generated from several sources. Speech enhancement can potentially benefit from the visual information from the target speaker, such as lip move-ment and facial expressions, because the visual aspect of speech isessentially unaffected by acoustic environment. In order to fuse audio and visual information, an audio-visual fusion strategy is proposed, which goes beyond simple feature concatenation and learns to automatically align the two modalities, leading to more powerful representation which increase intelligibility in noisy conditions. The proposed model fuses audio-visual featureslayer by layer, and feed these audio-visual features to each corresponding decoding layer. Experiment results show relative improvement from 6% to 24% on test sets over the audio modalityalone, depending on audio noise level. Moreover, there is a significant increase of PESQ from 1.21 to 2.06 in our -15 dB SNR experiment.