 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEPG: A Minimalist Ensemble Policy Gradient Framework for Deep Reinforcement Learning
Paper and Code
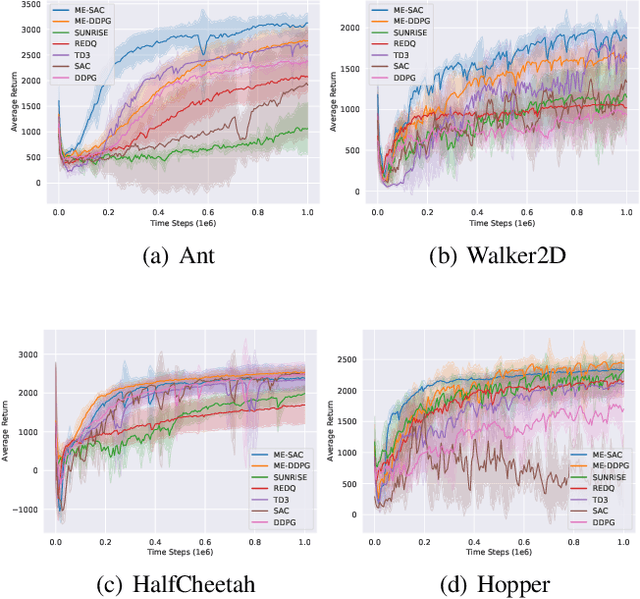
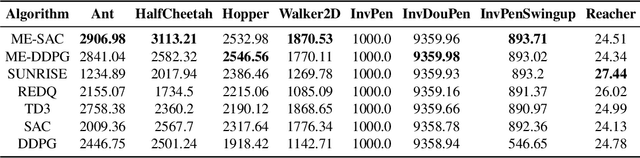

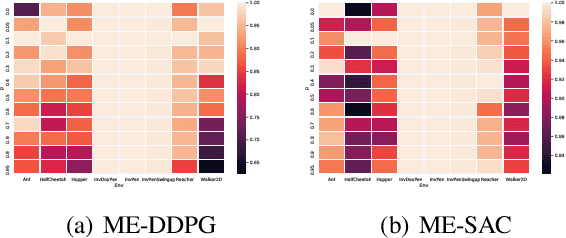
Ensemble reinforcement learning (RL) aims to mitigate instability in Q-learning and to learn a robust policy, which introduces multiple value and policy functions. In this paper, we consider finding a novel but simple ensemble Deep RL algorithm to solve the resource consumption issue. Specifically, we consider integrating multiple models into a single model. To this end, we propose the \underline{M}inimalist \underline{E}nsemble \underline{P}olicy \underline{G}radient framework (MEPG), which introduces minimalist ensemble consistent Bellman update. And we find one value network is sufficient in our framework. Moreover, we theoretically show that the policy evaluation phase in the MEPG is mathematically equivalent to a deep Gaussian Process. To verify the effectiveness of the MEPG framework, we conduct experiments on the gym simulator, which show that the MEPG framework matches or outperforms the state-of-the-art ensemble methods and model-free methods without additional computational resource costs.