 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEM: Multi-Modal Elevation Mapping for Robotics and Learning
Paper and Code
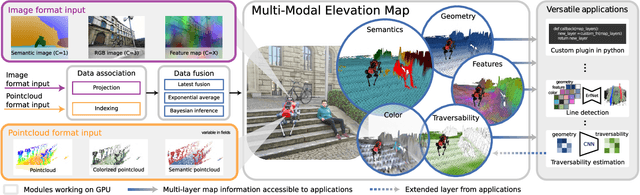
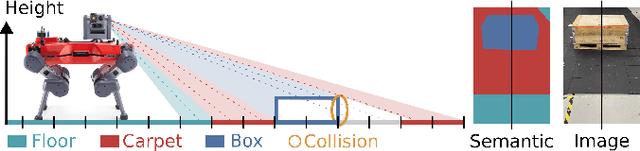

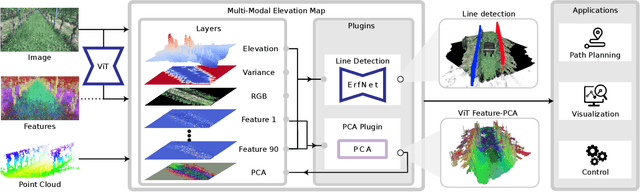
Elevation maps are commonly used to represent the environment of mobile robots and are instrumental for locomotion and navigation tasks. However, pure geometric information is insufficient for many field applications that require appearance or semantic information, which limits their applicability to other platforms or domains. In this work, we extend a 2.5D robot-centric elevation mapping framework by fusing multi-modal information from multiple sources into a popular map representation. The framework allows inputting data contained in point clouds or images in a unified manner. To manage the different nature of the data, we also present a set of fusion algorithms that can be selected based on the information type and user requirements. Our system is designed to run on the GPU, making it real-time capable for various robotic and learning tasks. We demonstrate the capabilities of our framework by deploying it on multiple robots with varying sensor configurations and showcasing a range of applications that utilize multi-modal layers, including line detection, human detection, and colorization.