 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMel-FullSubNet: Mel-Spectrogram Enhancement for Improving Both Speech Quality and ASR
Paper and Code
Feb 22, 2024
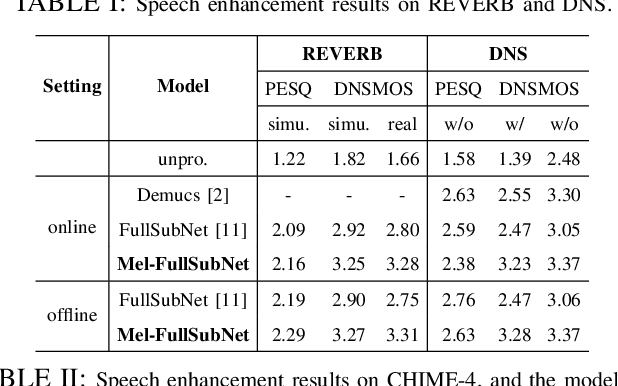


In this work, we propose Mel-FullSubNet, a single-channel Mel-spectrogram denoising and dereverberation network for improving both speech quality and automatic speech recognition (ASR) performance. Mel-FullSubNet takes as input the noisy and reverberant Mel-spectrogram and predicts the corresponding clean Mel-spectrogram. The enhanced Mel-spectrogram can be either transformed to speech waveform with a neural vocoder or directly used for ASR. Mel-FullSubNet encapsulates interleaved full-band and sub-band networks, for learning the full-band spectral pattern of signals and the sub-band/narrow-band properties of signals, respectively. Compared to linear-frequency domain or time-domain speech enhancement, the major advantage of Mel-spectrogram enhancement is that Mel-frequency presents speech in a more compact way and thus is easier to learn, which will benefit both speech quality and ASR. Experimental results demonstrate a significant improvement in both speech quality and ASR performance achieved by the proposed model.