 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedDG: A Large-scale Medical Consultation Dataset for Building Medical Dialogue System
Paper and Code
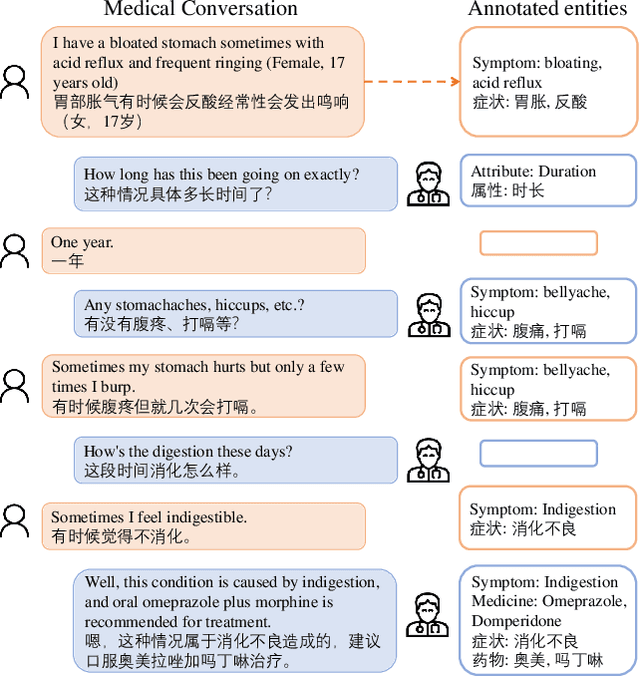

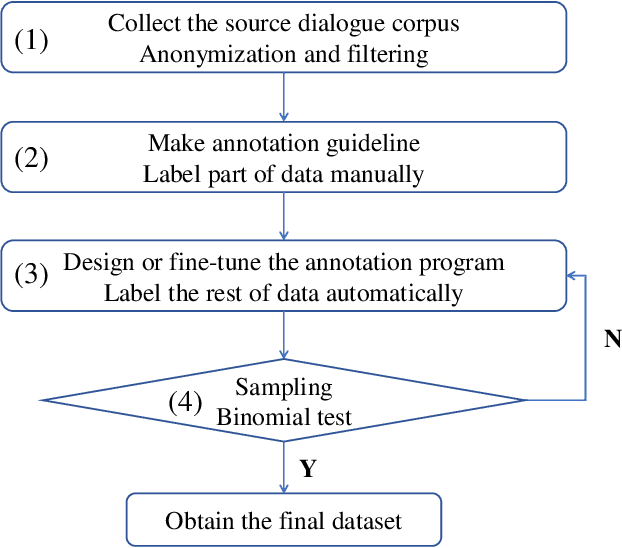
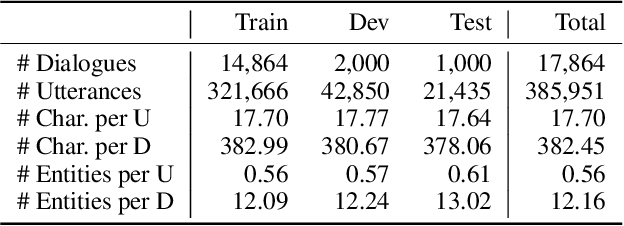
Developing conversational agents to interact with patients and provide primary clinical advice has attracted increasing attention due to its huge application potential, especially in the time of COVID-19 Pandemic. However, the training of end-to-end neural-based medical dialogue system is restricted by an insufficient quantity of medical dialogue corpus. In this work, we make the first attempt to build and release a large-scale high-quality Medical Dialogue dataset related to 12 types of common Gastrointestinal diseases named MedDG, with more than 17K conversations collected from the online health consultation community. Five different categories of entities, including diseases, symptoms, attributes, tests, and medicines, are annotated in each conversation of MedDG as additional labels. To push forward the future research on building expert-sensitive medical dialogue system, we proposes two kinds of medical dialogue tasks based on MedDG dataset. One is the next entity prediction and the other is the doctor response generation. To acquire a clear comprehension on these two medical dialogue tasks, we implement several state-of-the-art benchmarks, as well as design two dialogue models with a further consideration on the predicted entities. Experimental results show that the pre-train language models and other baselines struggle on both tasks with poor performance in our dataset, and the response quality can be enhanced with the help of auxiliary entity information. From human evaluation, the simple retrieval model outperforms several state-of-the-art generative models, indicating that there still remains a large room for improvement on generating medically meaningful responses.