 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskLab: Instance Segmentation by Refining Object Detection with Semantic and Direction Features
Paper and Code

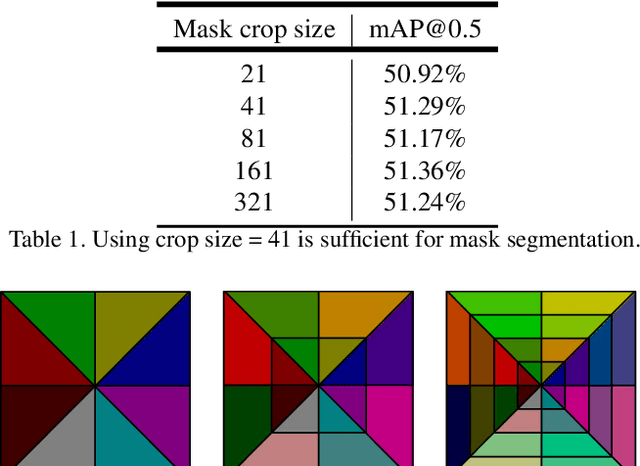
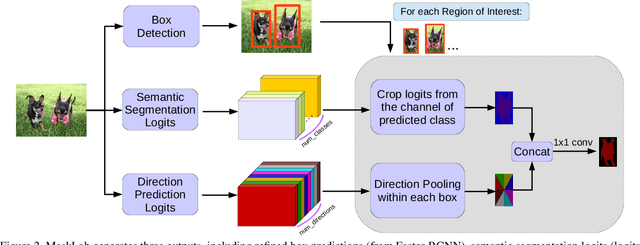

In this work, we tackle the problem of instance segmentation, the task of simultaneously solving object detection and semantic segmentation. Towards this goal, we present a model, called MaskLab, which produces three outputs: box detection, semantic segmentation, and direction prediction. Building on top of the Faster-RCNN object detector, the predicted boxes provide accurate localization of object instances. Within each region of interest, MaskLab performs foreground/background segmentation by combining semantic and direction prediction. Semantic segmentation assists the model in distinguishing between objects of different semantic classes including background, while the direction prediction, estimating each pixel's direction towards its corresponding center, allows separating instances of the same semantic class. Moreover, we explore the effect of incorporating recent successful methods from both segmentation and detection (i.e. atrous convolution and hypercolumn). Our proposed model is evaluated on the COCO instance segmentation benchmark and shows comparable performance with other state-of-art models.