 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Autoencoders for Point Cloud Self-supervised Learning
Paper and Code
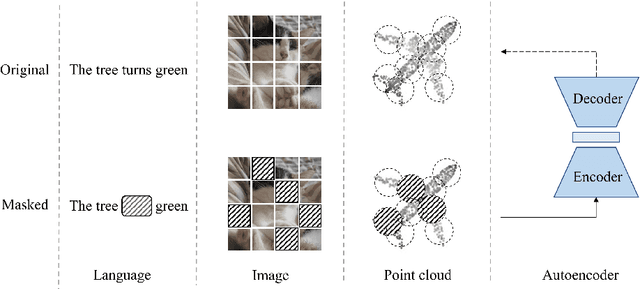
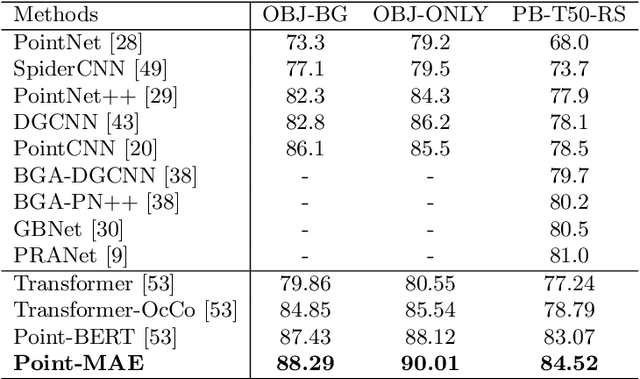
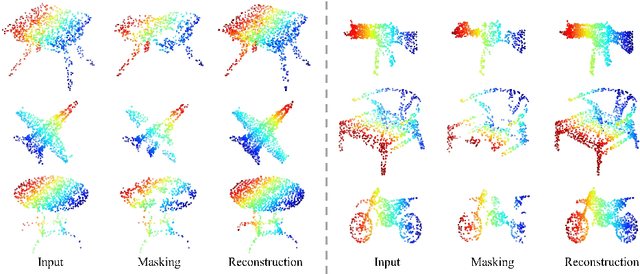
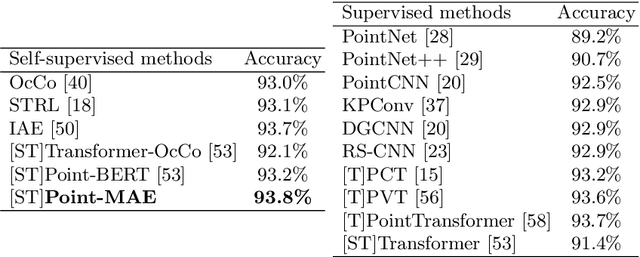
As a promising scheme of self-supervised learning, masked autoencoding has significantly advanced natural language processing and computer vision. Inspired by this, we propose a neat scheme of masked autoencoders for point cloud self-supervised learning, addressing the challenges posed by point cloud's properties, including leakage of location information and uneven information density. Concretely, we divide the input point cloud into irregular point patches and randomly mask them at a high ratio. Then, a standard Transformer based autoencoder, with an asymmetric design and a shifting mask tokens operation, learns high-level latent features from unmasked point patches, aiming to reconstruct the masked point patches. Extensive experiments show that our approach is efficient during pre-training and generalizes well on various downstream tasks. Specifically, our pre-trained models achieve 85.18% accuracy on ScanObjectNN and 94.04% accuracy on ModelNet40, outperforming all the other self-supervised learning methods. We show with our scheme, a simple architecture entirely based on standard Transformers can surpass dedicated Transformer models from supervised learning. Our approach also advances state-of-the-art accuracies by 1.5%-2.3% in the few-shot object classification. Furthermore, our work inspires the feasibility of applying unified architectures from languages and images to the point cloud.