 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarkov Logic Networks for Natural Language Question Answering
Paper and Code
Jul 10, 2015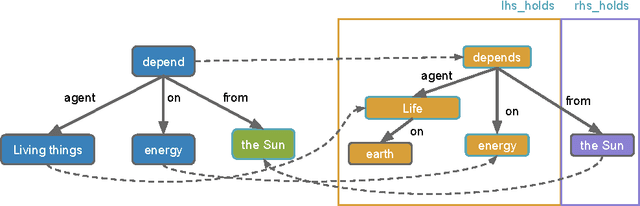
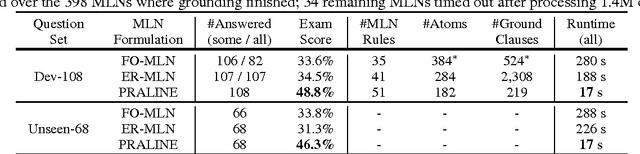
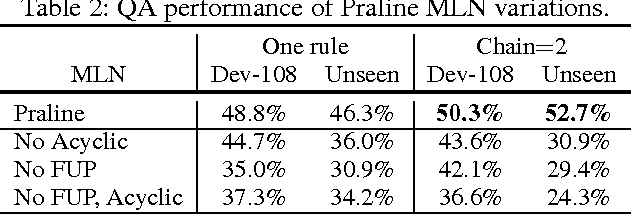
Our goal is to answer elementary-level science questions using knowledge extracted automatically from science textbooks, expressed in a subset of first-order logic. Given the incomplete and noisy nature of these automatically extracted rules, Markov Logic Networks (MLNs) seem a natural model to use, but the exact way of leveraging MLNs is by no means obvious. We investigate three ways of applying MLNs to our task. In the first, we simply use the extracted science rules directly as MLN clauses. Unlike typical MLN applications, our domain has long and complex rules, leading to an unmanageable number of groundings. We exploit the structure present in hard constraints to improve tractability, but the formulation remains ineffective. In the second approach, we instead interpret science rules as describing prototypical entities, thus mapping rules directly to grounded MLN assertions, whose constants are then clustered using existing entity resolution methods. This drastically simplifies the network, but still suffers from brittleness. Finally, our third approach, called Praline, uses MLNs to align the lexical elements as well as define and control how inference should be performed in this task. Our experiments, demonstrating a 15\% accuracy boost and a 10x reduction in runtime, suggest that the flexibility and different inference semantics of Praline are a better fit for the natural language question answering task.