 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAP-Gen: An Automated 3D-Box Annotation Flow with Multimodal Attention Point Generator
Paper and Code
Mar 29, 2022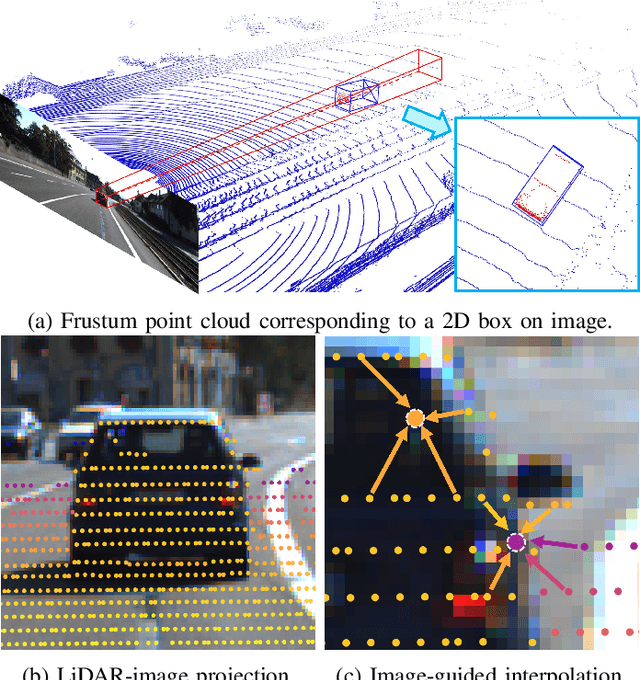
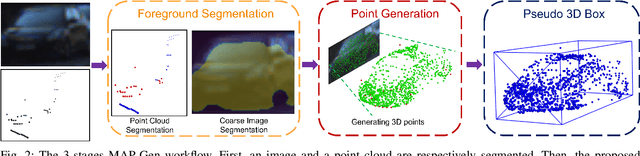
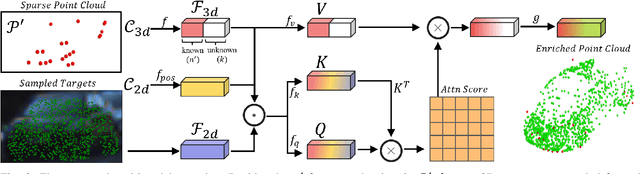
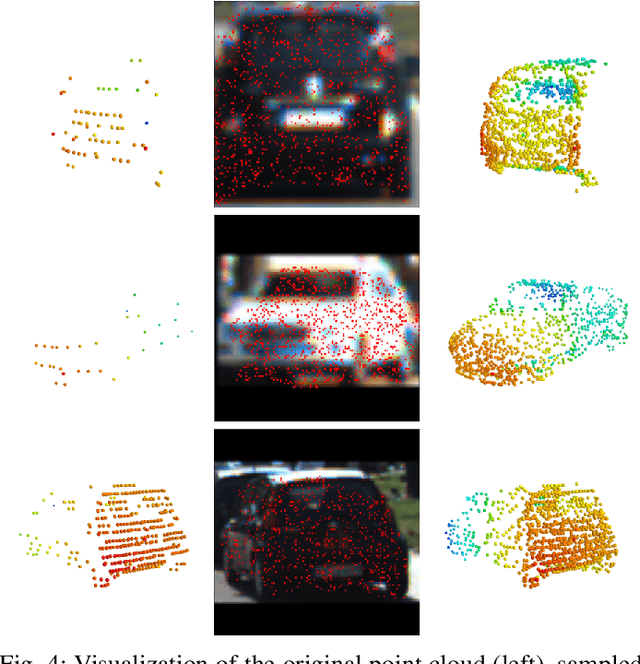
Manually annotating 3D point clouds is laborious and costly, limiting the training data preparation for deep learning in real-world object detection. While a few previous studies tried to automatically generate 3D bounding boxes from weak labels such as 2D boxes, the quality is sub-optimal compared to human annotators. This work proposes a novel autolabeler, called multimodal attention point generator (MAP-Gen), that generates high-quality 3D labels from weak 2D boxes. It leverages dense image information to tackle the sparsity issue of 3D point clouds, thus improving label quality. For each 2D pixel, MAP-Gen predicts its corresponding 3D coordinates by referencing context points based on their 2D semantic or geometric relationships. The generated 3D points densify the original sparse point clouds, followed by an encoder to regress 3D bounding boxes. Using MAP-Gen, object detection networks that are weakly supervised by 2D boxes can achieve 94~99% performance of those fully supervised by 3D annotations. It is hopeful this newly proposed MAP-Gen autolabeling flow can shed new light on utilizing multimodal information for enriching sparse point clouds.