 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManifold Modeling in Embedded Space: A Perspective for Interpreting "Deep Image Prior"
Paper and Code
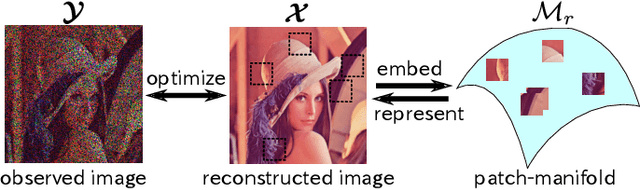
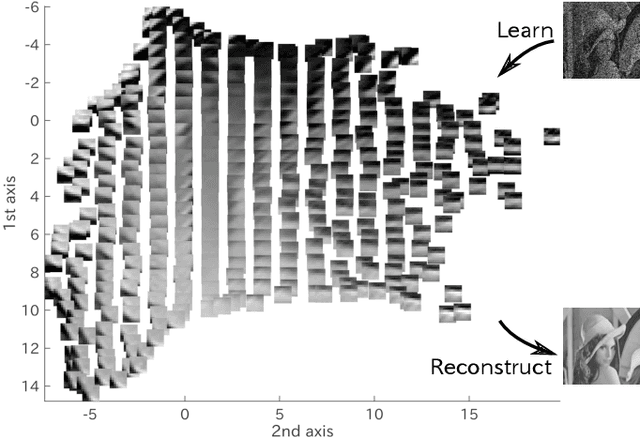
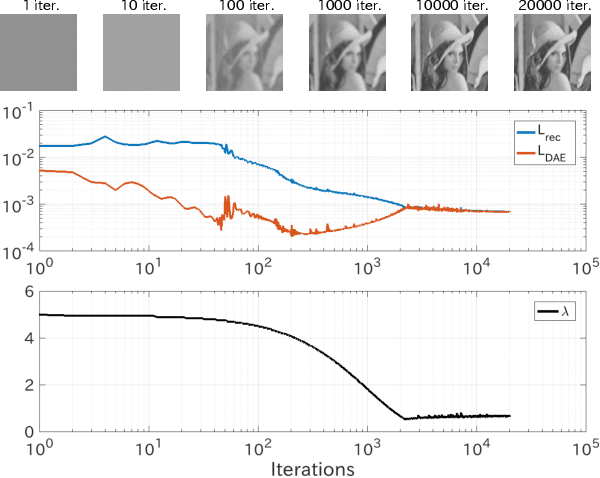

Deep image prior (DIP), which utilizes a deep convolutional network (ConvNet) structure itself as an image prior, has attractive attentions in computer vision community. It empirically showed that the effectiveness of ConvNet structure in various image restoration applications. However, why the DIP works so well is still in black box, and why ConvNet is essential for images is not very clear. In this study, we tackle this question by considering the convolution divided into "embedding" and "transformation", and proposing a simple, but essential, modeling approach of images/tensors related with dynamical system or self-similarity. The proposed approach named as manifold modeling in embedded space (MMES) can be implemented by using a denoising-auto-encoder in combination with multiway delay-embedding transform. In spite of its simplicity, the image/tensor completion and super-resolution results of MMES were very similar even competitive with DIP in our experiments, and these results would help us for reinterpreting/characterizing the DIP from a perspective of "smooth patch-manifold prior".