 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMANGO: A Mask Attention Guided One-Stage Scene Text Spotter
Paper and Code
Dec 08, 2020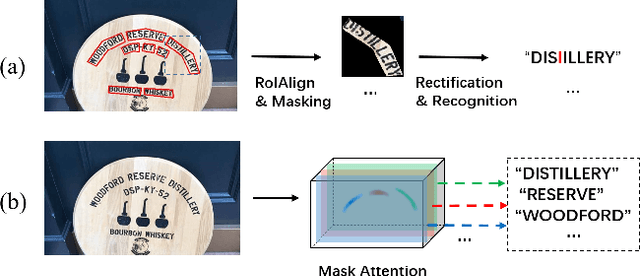
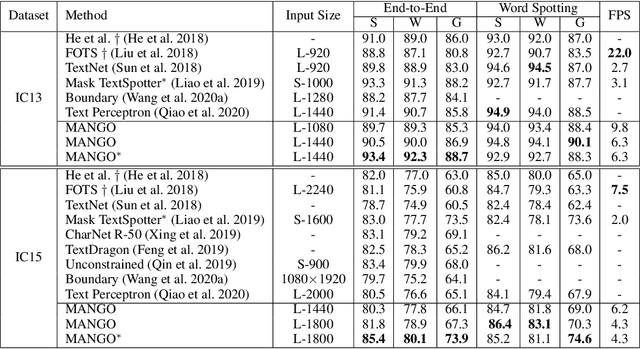
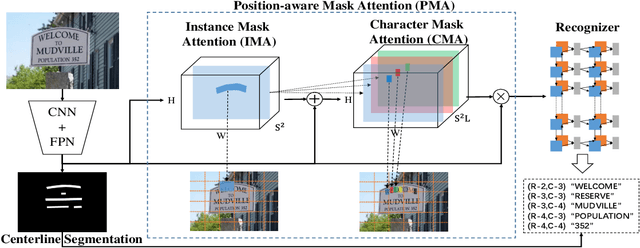
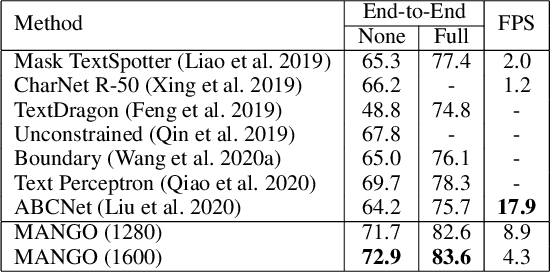
Recently end-to-end scene text spotting has become a popular research topic due to its advantages of global optimization and high maintainability in real applications. Most methods attempt to develop various region of interest (RoI) operations to concatenate the detection part and the sequence recognition part into a two-stage text spotting framework. However, in such framework, the recognition part is highly sensitive to the detected results (\emph{e.g.}, the compactness of text contours). To address this problem, in this paper, we propose a novel Mask AttentioN Guided One-stage text spotting framework named MANGO, in which character sequences can be directly recognized without RoI operation. Concretely, a position-aware mask attention module is developed to generate attention weights on each text instance and its characters. It allows different text instances in an image to be allocated on different feature map channels which are further grouped as a batch of instance features. Finally, a lightweight sequence decoder is applied to generate the character sequences. It is worth noting that MANGO inherently adapts to arbitrary-shaped text spotting and can be trained end-to-end with only coarse position information (\emph{e.g.}, rectangular bounding box) and text annotations. Experimental results show that the proposed method achieves competitive and even new state-of-the-art performance on both regular and irregular text spotting benchmarks, i.e., ICDAR 2013, ICDAR 2015, Total-Text, and SCUT-CTW1500.