 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMamba-Based Graph Convolutional Networks: Tackling Over-smoothing with Selective State Space
Paper and Code
Jan 26, 2025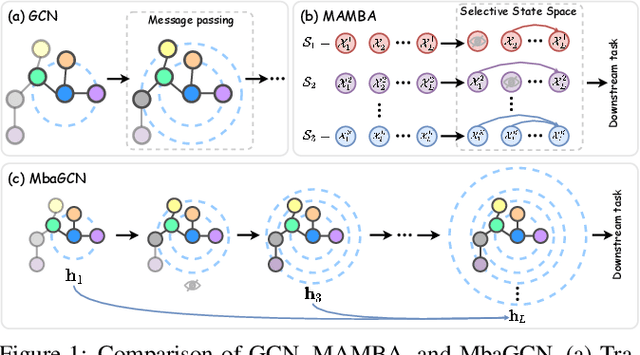
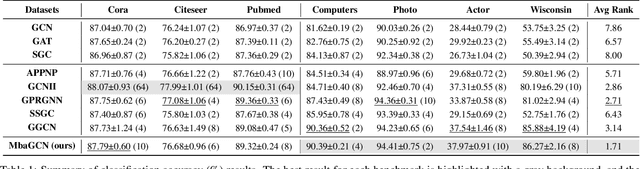
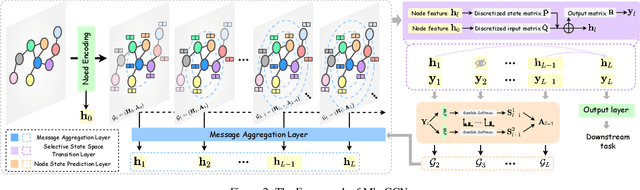
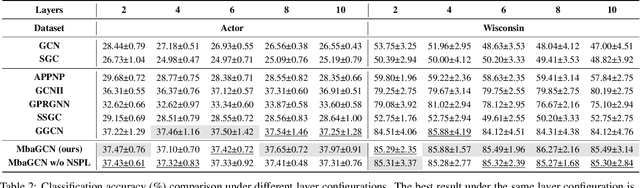
Graph Neural Networks (GNNs) have shown great success in various graph-based learning tasks. However, it often faces the issue of over-smoothing as the model depth increases, which causes all node representations to converge to a single value and become indistinguishable. This issue stems from the inherent limitations of GNNs, which struggle to distinguish the importance of information from different neighborhoods. In this paper, we introduce MbaGCN, a novel graph convolutional architecture that draws inspiration from the Mamba paradigm-originally designed for sequence modeling. MbaGCN presents a new backbone for GNNs, consisting of three key components: the Message Aggregation Layer, the Selective State Space Transition Layer, and the Node State Prediction Layer. These components work in tandem to adaptively aggregate neighborhood information, providing greater flexibility and scalability for deep GNN models. While MbaGCN may not consistently outperform all existing methods on each dataset, it provides a foundational framework that demonstrates the effective integration of the Mamba paradigm into graph representation learning. Through extensive experiments on benchmark datasets, we demonstrate that MbaGCN paves the way for future advancements in graph neural network research.