 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Resource Multi-modal Data Augmentation for End-to-end ASR
Paper and Code
Dec 10, 2018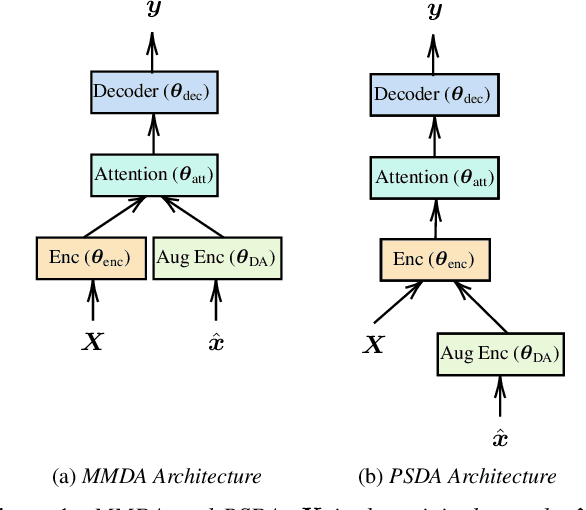
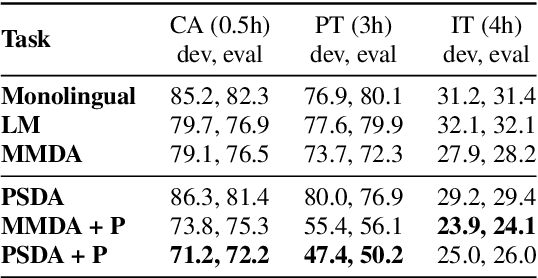

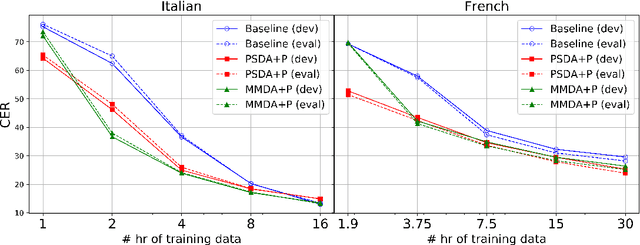
We explore training attention-based encoder-decoder ASR for low-resource languages and present techniques that result in a 50% relative improvement in character error rate compared to a standard baseline. The performance of encoder-decoder ASR systems depends on having sufficient target-side text to train the attention and decoder networks. The lack of such data in low-resource contexts results in severely degraded performance. In this paper we present a data augmentation scheme tailored for low-resource ASR in diverse languages. Across 3 test languages, our approach resulted in a 20% average relative improvement over a baseline text-based augmentation technique. We further compare the performance of our monolingual text-based data augmentation to speech-based data augmentation from nearby languages and find that this gives a further 20-30% relative reduction in character error rate.