 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Latency Speaker-Independent Continuous Speech Separation
Paper and Code
Apr 13, 2019


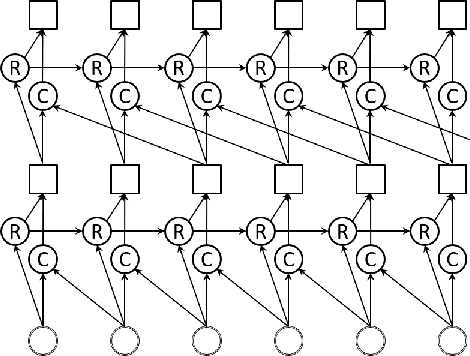
Speaker independent continuous speech separation (SI-CSS) is a task of converting a continuous audio stream, which may contain overlapping voices of unknown speakers, into a fixed number of continuous signals each of which contains no overlapping speech segment. A separated, or cleaned, version of each utterance is generated from one of SI-CSS's output channels nondeterministically without being split up and distributed to multiple channels. A typical application scenario is transcribing multi-party conversations, such as meetings, recorded with microphone arrays. The output signals can be simply sent to a speech recognition engine because they do not include speech overlaps. The previous SI-CSS method uses a neural network trained with permutation invariant training and a data-driven beamformer and thus requires much processing latency. This paper proposes a low-latency SI-CSS method whose performance is comparable to that of the previous method in a microphone array-based meeting transcription task.This is achieved (1) by using a new speech separation network architecture combined with a double buffering scheme and (2) by performing enhancement with a set of fixed beamformers followed by a neural post-filter.